






 BTC/HKD+0.82%
BTC/HKD+0.82% ETH/HKD+1.64%
ETH/HKD+1.64% LTC/HKD+1.16%
LTC/HKD+1.16% DOT/HKD+2.53%
DOT/HKD+2.53% ADA/HKD+3.52%
ADA/HKD+3.52% SOL/HKD+2.65%
SOL/HKD+2.65% XRP/HKD+2.74%
XRP/HKD+2.74% DOGE/US+1.67%
DOGE/US+1.67%實用性拜占庭容錯算法,是一種在信道可靠的情況下解決拜占庭將軍問題的實用方法。拜占庭將軍問題最早由LeslieLamport等人在1982年發表的論文提出,論文中證明了在將軍總數n大于3f,背叛者為f或者更少時,忠誠的將軍可以達成命令上的一致,即3f+1<=n,算法復雜度為O(n^(f+1))。隨后MiguelCastro和BarbaraLiskov在1999年發表的論文中首次提出PBFT算法,該算法容錯數量也滿足3f+1<=n,算法復雜度降低到了O(n^2)。
如果對于PBFT共識算法有所了解,對節點總數n與容錯上限f的關系可能會比較熟悉:在系統內最多存在f個錯誤節點的前提下,系統內總節點數量n應該滿足n>3f,在推進共識過程中則需要收集一定數目的投票,才能完成認證過程。在本節當中,我們將首先討論這些數值間關系該如何得出。
--Quorum機制--
在有冗余數據的分布式存儲系統當中,冗余數據對象會在不同的機器之間存放多份拷貝。但是在同一時刻,一個數據對象的多份拷貝只能用于讀或者寫。為了保持數據冗余與一致性,需要對應的投票機制進行維持,這就是Quorum機制。區塊鏈作為一種分布式系統,同樣也需要該機制進行集群維護。
為了更好地理解Quorum機制,我們先來了解一種與之類似,但是更加極端的投票機制——WARO機制。使用WARO機制維護節點總數為n的集群時,節點執行寫操作的“票數”應當為n,而讀操作時的“票數”可以設置為1。也就是說,在執行寫入時,需要保證全部節點完成寫入操作才可視該操作為完成,否則會寫入失敗;相應地,在執行讀操作時,只需要讀取一個節點的狀態,就可以對該系統狀態進行確認。可以看到,在使用WARO機制的集群中,寫操作的執行非常脆弱:只要有一個節點執行寫入失敗,那么這次操作就無法完成。不過,雖然犧牲了寫操作健壯性,但是,在WARO機制下,對于該集群執行讀操作會非常容易。
Quorum機制就是對讀寫操作的折衷考慮,對于同一份數據對象的每一份拷貝,不會被超過兩個訪問對象讀寫,并且權衡讀寫時的集合大小要求。在一個分布式集群當中,每一份數據拷貝對象都被賦予了一票。假設:
系統中有V票,這就意味著一個數據對象有V份冗余拷貝;
對于每一個讀操作,獲得的票數必須不小于最小讀票數R才可以成功讀取;
對于每個寫操作,獲得的票數必須不小于最小寫票數W才可以成功寫入。
此時,為了維持集群一致性,V、R、W應滿足不等關系,R+W>V且W>V/2。其中,R+W>V保證了一個數據不會被同時讀或寫。當一個寫操作請求傳入,它必須要獲得W票,而剩下的數量是V-W不足R,因此不會再處理讀請求。同理,當讀請求已經獲得了R票,寫請求就無法被處理。W>V/2,保證了數據的串行修改,也就是說,一份數據的冗余拷貝不可能同時被兩個寫請求修改。
YouTube網紅Logan Paul在針對NFT項目Crypto Zoo的集體訴訟中被點名:2月3日消息,You Tube網紅Logan Paul在一項擬議中的集體訴訟中被點名,該訴訟涉及Paul為NFT項目Crypto Zoo做銷售推廣,但相關產品從未推出。
“(被告)利用Paul的在線平臺向不熟悉數字貨幣產品的消費者推廣了CryptoZoo的產品,導致數萬人購買了上述產品,”訴訟文件寫道,客戶不知道,這款游戲沒有運行或從未存在過,被告為了自己的利益操縱了Zoo代幣市場。
原告律師聲稱,Paul和他的同事執行了“Rug Pull”。(CoinDesk)[2023/2/3 11:45:41]
對于集群中的共識節點,在推進共識算法時,參與共識的節點會同時對集群進行讀寫操作。為了平衡讀寫操作對于集合大小的要求,每個節點的R與W取同樣大小,記為Q。當集群中總共存在n個節點,并且其中最多出現f個錯誤節點的情況下,我們該如何計算n、f、Q之間的關系呢?接下來,我們將從最簡單的CFT場景出發,逐步探索如何在BFT場景中得到這些數值取值之間的關系。
▲CFT
CFT,表示系統中的節點只會出現宕機這種錯誤行為,任何節點不會主動發出錯誤消息。當我們在討論共識算法可靠性時,通常會關注算法兩種基本性質:活性與安全性。在計算Q的大小時,同樣也可以從這兩個角度出發進行考慮。
對于活性與安全性,有一種比較直觀的描述方式:
somethingeventuallyhappens,某個事件最終會發生
somethinggoodeventuallyhappens,這個最終會發生的事件合理
從活性角度出發,我們的集群需要能夠持續運行下去,不會由于某些節點的錯誤導致無法繼續共識。從安全性角度出發,我們的集群在共識推進的過程中,能夠持續獲得某個合理的結果,對于分布式系統來說,這種“合理”的結果,其最基本的要求就是集群整體狀態的一致性。
于是,在CFT場景下,對于Q數值的確定就變得簡單明確:
活性:由于我們需要保證集群能夠持續運行,所以,在任何場景下都要保證有獲取到Q票的可能性,從而為集合讀寫數據。由于集群中最多會有f個節點發生宕機,所以為了保證能獲取到Q票,該值的大小需要滿足:Q<=n-f。
安全性:由于我們需要保證集群不發生分歧,所以,按照Quorum機制的基本要求,需要滿足在上一節當中提到的兩個不等式,將Q作為最小讀集合與最小寫集合帶入該組不等式,此時,Q滿足不等關系,Q+Q>n且Q>n/2,因此,該值的大小需要滿足:Q>n/2。
▲BFT
IBM首席執行官:希望未來30年繼續投資中國:1月22日消息,世界經濟論壇2023年年會在瑞士達沃斯舉行。年會期間,IBM首席執行官艾維德·克里什納表示,IBM已經在中國投資了近30年,希望將在未來30年內繼續投資中國。
他相信,中國是全球經濟中一個不斷增長的部分。IBM在中國有很多偉大的客戶,希望為他們提供服務。(財聯社)[2023/1/23 11:26:21]
BFT,表示集群中的錯誤節點不僅可能會發生宕機,也可能存在惡意行為,即拜占庭行為,例如主動進行狀態分叉。在這種情況下,對于集群整體而言,只有n-f個節點的狀態可靠,當我們收集到Q個投票時,其中也只有Q-f個投票來自可靠的節點。因此,在安全性方面,BFT場景下需要保證狀態可靠的節點之間不會發生分歧,因此得到以下兩種關系:
活性:依然只需要保證每時每刻都有獲取Q票的可能性,因此,Q<=n-f。
安全性:對于全部保證正確的節點不會發生分歧,此時,應當滿足不等關系,(Q-f)+(Q-f)>n-f且(Q-f)>(n-f)/2,因此,此時Q的大小需要滿足的關系為,Q>(n+f)/2。
▲節點總數與容錯上限
對于節點總數n與容錯上限f,在PBFT論文當中給出的解釋:由于存在f個節點可能發生宕機,因此我們至少需要在收到n-f條消息時進行響應,而對于我們收到的來自n-f個節點的消息,由于其中最多可能存在f條消息來自于不可靠的拜占庭節點,因此需要滿足n-f-f>f,所以,n>3f。
簡單來說,PBFT的作者從集群活性與安全性出發,得到了節點總數與容錯上限之間的關系。上一節中,我們也是從活性與安全性角度,獲得了n、f與Q的關系,在這里也可以用來推導n與f的關系:為了同時滿足活性與安全性的要求,Q需要滿足不等關系,Q<=n-f且Q>(n+f)/2,因此,可以得到n與f之間的不等關系,(n+f)/2<n-f,也就是n>3f。
(通過類似的方式,也可以得到CFT場景中n與f的關系,n>2f。)
--PBFT與RBFT--
在理解BFT場景中n、f、Q的關系后,接下來進入到PBFT的介紹。在此之前,簡單提一下SMR復制狀態機。在該模型當中,對于不同的狀態機,如果從同樣的初始狀態出發,按照同樣的順序輸入同樣的指令集,那么它們得到的最終結果總會一致。對于共識算法而言,其只需要保證“按照同樣的順序輸入同樣的指令”,即可在各個狀態機上獲得同樣的狀態。而PBFT就是對指令執行順序的共識。
那么,PBFT是如何保證指令執行順序的一致性呢?PBFT集群為主從結構,由主節點提出提案,并通過集群中各個節點間的交互進行驗證,從而使得每個正確節點遵循同樣的順序對指令集進行執行。在這個交互過程中,就需要使用Quorum機制保證集群整體狀態的一致性。下面我們將對PBFT進行詳細介紹。
Amber Group和Auros成為Ribbon Lend第二批借款人機構:11月7日消息,鏈上結構化產品Ribbon Finance關于其DeFi借貸產品Ribbon Lend第二批借款人的社區投票已經結束,Amber Group和Auros在四個機構中勝出,成為Ribbon Lend第二批借款人機構。[2022/11/7 12:28:35]
▲兩階段共識
相比較常見的“三階段“概念,將PBFT視為一種兩階段共識協議或許更能體現每個階段的目的:提案階段和提交階段。在每個階段中,各個節點都需要收集來自Q個節點一致的投票后,才會進入到下一個階段。為了更方便討論,這里將討論節點總數為3f+1時的場景,此時,讀寫集票數Q為2f+1。
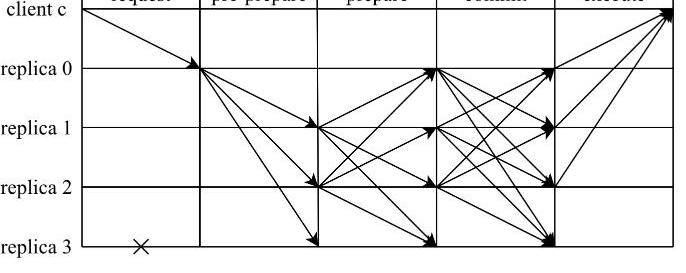
1)提案階段
在該階段中,由主節點發送pre-prepare發起共識,由從節點發送prepare對主節點的提案進行確認。主節點在收到客戶端的請求后,會主動向其它節點廣播pre-prepare消息<pre-prepare,v,n,D(m)>
v為當前視圖
n為主節點分配的請求序號
D(m)為消息摘要
m為消息本身
從節點在收到pre-prepare消息之后,會對該消息進行合法性驗證,若通過驗證,那么該節點就會進入pre-prepared狀態,表示該請求在從節點處通過合法性驗證。否則,從節點會拒絕該請求,并觸發視圖切換流程。當從節點進入到pre-prepared狀態后,會向其它節點廣播prepare消息<prepare,v,n,D(m),i>,
i為當前節點標識序號
其他節點收到消息后,如果該請求已經在當前節點進入pre-prepared狀態,并且收到2f條來自不同節點對應的prepare消息,從而進入到prepared狀態,提案階段完成。此時,有2f+1個節點認可將序號n分配給消息m,這就意味著,該共識集群已經將序號n分配給消息m。
2)提交階段
當請求在當前節點進入prepared狀態后,本節點會向其它節點廣播commit消息<commit,v,n,i>。如果該請求已經在當前節點達到prepared狀態,并且收到2f+1條來自不同節點對應的commit消息(包含自身),那么該請求就會進入到committed狀態,并可以進行執行。此時,有2f+1個節點已經得知共識集群已經將序號n分配給消息m。執行完畢后,節點會將執行結果反饋給客戶端進行后續判斷。
以太坊地址總數突破2.5億個:金色財經報道,據OKlink數據顯示,以太坊地址總數已突破2.5億個,本文撰寫是為254,421,836個,過去24小時增加71,489個,其中普通地址數203,492,770個,持幣地址數86,487,304個,活躍地址數526,457個。此外,以太坊合約地址數已超過5000萬,截至目前為50,929,035個。[2022/9/14 13:28:06]
▲檢查點機制
PBFT共識算法在運行過程中,會產生大量的共識數據,因此需要執行合理的垃圾回收機制,及時清理多余的共識數據。為了達成這個目的,PBFT算法設計了checkpoint流程,用于進行垃圾回收。
checkpoint即檢查點,這是檢查集群是否進入穩定狀態的流程。在進行檢查時,節點廣播checkpoint消息<checkpoint,n,d,i>
n為當前請求序號
d為消息執行后獲得的摘要
i為當前節點表示
當節點收到來自不同節點的2f+1條有相同<n,d>的checkpoint消息后,即可認為,當前集群對于序號n進入了穩定檢查點。此時,將不再需要stablecheckpoint之前的共識數據,可以對其進行清理。不過,如果為了進行垃圾回收而頻繁執行checkpoint,那么將會對系統運行帶來明顯負擔。所以,PBFT為checkpoint流程設計了執行間隔,設定每執行k個請求后,節點就主動發起一次checkpoint,來獲取最新的stablecheckpoint。
除此之外,PBFT引入了高低水位的概念,用于輔助進行垃圾回收。在共識進行的過程中,由于節點之間的性能差距,可能會出現節點間運行速率差異過大的情況。部分節點執行的序號可能會領先于其他節點,導致于領先節點的共識數據長時間得不到清理,造成內存占用過大的問題,而高低水位的作用就是對集群整體的運行速率進行限制,從而限制了節點的共識數據大小。
高低水位系統中,低水位記為h,通常指的是最近一次的stablecheckpoint對應的高度。高水位記為H,計算方式為H=h+L,L代表了共識緩存數據的最大限度,通常為checkpoint間隔K的整數倍。當節點產生的checkpoint達到到stablecheckpoint狀態時,節點將更新低水位h。在執行到最高水位H時,如果低水位h沒有被更新,節點會暫停執行序號更大的請求,等待其他節點的執行,待低水位h更新后重新開始執行更大序號的請求。
▲視圖變更
當主節點超時無響應或者從節點集體認為主節點是問題節點時,就會觸發視圖變更。視圖變更完成后,視圖編號將會加1,隨之主節點也會切換到下一個節點。如圖所示,節點0發生異常觸發視圖變更流程,變更完成后,節點1成為新的主節點。
ETC鏈上總鎖倉量突破70萬美元,24H漲幅117.06%:8月17日消息,DeFiLlama數據顯示,Ethereum Classic(ETC)鏈上總鎖倉量(TVL)突破70萬美元,目前為707647美元,24小時漲幅117.06%。[2022/8/17 12:31:47]
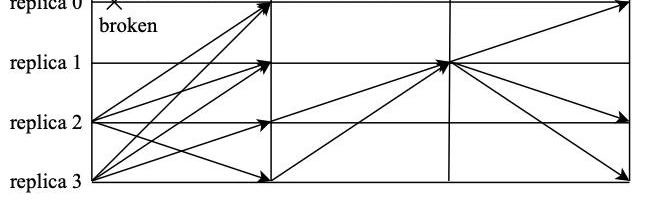
當視圖變更發生時,節點會主動進入到新視圖v+1中,并廣播view-change消息,請求進行主節點切換。此時,共識集群需要保證,在舊視圖中已經完成共識的請求能夠在新視圖中得到保留。因此,在視圖變更請求中,一般需要附加部分舊視圖中的共識日志,節點廣播的請求為<viewchange,v+1,h,C,P,Q,i>
i為發送者節點的身份標識
v+1表示請求進入的新視圖
h為當前節點最近一次的穩定檢查點的高度
C:當前節點已經執行過的檢查點的集合,數據按照<n,d>的方式進行存儲,表示當前節點已經執行過序號為n摘要為d的checkpoint檢查,并發送過相應的共識消息。
P:在當前節點已經達成prepared狀態的請求的集合,即,當前節點已經針對該請求收到了1條pre-prepare消息與2f條prepare消息。在集合P中,數據按照<n,d,v>的方式進行存儲,表示在視圖v中,摘要為d序號為n的請求已經進入了prepared狀態。由于請求已經達成了prepared狀態,說明至少有2f+1個節點擁有并且認可該請求,只差commit階段即可完成一致性確認,因此,在新的視圖中,這一部分消息可以直接使用原本的序號,無需分配新序號。
Q:在當前節點已經達成pre-prepared狀態的請求的集合,即,當前節點已經針對該請求發送過對應的pre-prepare或prepare消息。在集合Q中,數據同樣按照<n,d,v>的方式進行存儲。由于請求已經進入pre-prepared狀態,表示該請求已經被當前節點認可。
但是,視圖v+1對應的新主節點P在收到其他節點發送的view-change消息后,無法確認view-change消息是否拜占庭節點發出的,也就無法保證一定使用正確的消息進行決策。PBFT通過view-change-ack消息讓所有節點對所有它收到的view-change消息進行檢查和確認,然后將確認的結果發送給P。主節點P統計view-change-ack消息,可以辨別哪些view-change是正確的,哪些是拜占庭節點發出的。
節點在對view-change消息進行確認時,會對其中的P、Q集合進行檢查,要求集合中的請求消息小于等于視圖v,若滿足要求,就會發送view-change-ack消息<viewchange-ack,v+1,i,j,d>
i為發送ack消息的節點標識
j為要確認的view-change消息的發送者標識
d為要確認的view-change消息的摘要
不同于一般消息的廣播,這里不再使用數字簽名標識消息的發送方,而是采用會話密鑰保證當前節點與主節點通信的可信,從而幫助主節點判定view-change消息的可信性。
新的主節點P維護了一個集合S,用來存放驗證正確的view-change消息。當P獲取到一條view-change消息以及合計2f-1條對應的view-change-ack消息時,就會將這條view-change消息加入到集合S。當集合S的大小達到2f+1時,證明有足夠多的非拜占庭節點發起視圖變更。主節點P會按照收到的view-change消息,產生new-view消息并廣播,<new-view,v+1,V,X>
V:視圖變更驗證集合,按照<i,d>的方式進行存儲,表示節點i發送的view-change消息摘要為d,均與集合S中的消息相對應,其他節點可以使用該集合中的摘要以及節點標識,確認本次視圖變更的合法性。
X:包含穩定檢查點以及選入新視圖的請求。新的主節點P會按照集合中S的view-change消息進行計算,根據其中的C、P、Q集合,確定最大穩定檢查點以及需要保留到新視圖中的請求,并將其寫入集合X中,具體選定過程相對繁瑣,如果有興趣,讀者可以參閱原始論文。
▲改進空間與RBFT
RBFT,是趣鏈科技基于PBFT為企業級聯盟鏈平臺研發的高魯棒性共識算法。相比較PBFT來說,我們在共識消息處理、節點狀態恢復、集群動態維護等多方面進行了優化改良,使得RBFT共識算法能夠應對更復雜多樣的實際場景。
1)交易池
包括RBFT在內,許多共識算法的工業實現中,都設計了獨立的交易池模塊。在收到交易后,將交易本身存放在交易池里,并通過交易池對交易進行共享,使得各個共識節點都能獲得共享的交易。在共識的過程中,只需對交易哈希進行共識即可。
在處理較大交易時,交易池對于共識的穩定性有不錯的提升。將交易池與共識算法本身進行解耦,也更方便通過交易池實現更多的功能特性,比如交易去重。
2)主動恢復
在PBFT中,當節點借由checkpoint或view-change發現自身的低水位落后,即穩定檢查點落后時,落后節點就會觸發相應的恢復過程,以拉取該穩定檢查點之前的數據。這樣的落后恢復機制有一些不足:一方面,該恢復流程的觸發是被動的,需要在checkpoint過程或者觸發view-change完成時才能觸發落后恢復;另一方面,對于落后節點來說,如果通過checkpoint發現自身穩定檢查點落后時,落后節點只能恢復到最新的穩定檢查點,而無法獲得該檢查點后落后的共識消息,可能一直無法真正參與到共識當中。
在RBFT中,我們設計了主動的節點恢復機制:一方面,該恢復機制可以主動觸發,更快地幫助落后節點進行恢復;另一方面,在恢復到最新的穩定檢查點基礎之上,我們設計了水位間的恢復機制,從而使得落后節點能夠獲取到最新的共識消息,更快地參與到正常共識流程。
3)集群動態維護
Raft作為一種廣泛應用在工程中的共識算法,其重要優勢之一,就是能夠動態完成集群成員變更。而PBFT沒有給出集群成員動態變更方案,在實際應用中存在不足。在RBFT中,我們設計了一種動態變更集群成員的方案,使得不需要停啟集群整體的情況下,就可以對集群成員進行增刪。
新增或刪除節點時,由管理員向集群發交易創建操作節點的提案,并等待其他管理員投票,投票通過后由創建提案的管理員再次向集群發執行提案配置交易,執行時會更改集群配置。
對于共識部分,當處理執行提案配置交易時,集群中的節點將進入配置變更狀態,不再打包其他交易。主節點將該交易單獨打包生成配置包,并對該配置包進行共識。當該配置包完成共識,它將被執行并生成配置區塊。為了保證改配置區塊不可回滾,共識層將等待改配置包的執行結果,確定集群中已經對于該配置包所在高度形成穩定檢查點,才會解除節點的配置狀態,繼續進行其他交易的打包。
對于集群不同的配置狀態,我們通過世代進行區分。不同世代擁有其獨立的編號,該編號為單調遞增的,每次執行完成一筆執行提案配置交易,將會對世代編號進行更新。對于集群中不同的節點,如果它們處于同一個世代下,則可以進行正常的信息交互。否則,節點之間只能進行狀態恢復相關消息的交互。由于配置變更的信息已經被寫入鏈上,因此,我們可以通過直接同步區塊的方式為落后節點進行配置更新。通過上一節所說的主動恢復協議,世代落后的節點可以獲取到最新的狀態,并通過直接同步區塊的方式恢復至最新的穩定檢查點,同時完成節點世代與配置狀態的恢復。
通過這樣的動態變更集群成員的方式,使得集群配置維護更加可靠與便捷,并且可以為動態修改更多配置信息提供了可能。
作者簡介
王廣任
趣鏈科技基礎平臺部共識算法研究小組
參考文獻
LamportL,ShostakR,PeaseM.TheByzantinegeneralsproblem//Concurrency:theWorksofLeslieLamport.2019:203-226.
CastroM,LiskovB.PracticalByzantinefaulttolerance//OSDI.1999,99(1999):173-186.
https://en.wikipedia.org/wiki/Quorum_(distributed_computing)
OwickiS,LamportL.Provinglivenesspropertiesofconcurrentprograms.ACMTransactionsonProgrammingLanguagesandSystems(TOPLAS),1982,4(3):455-495.
FredB.Schneider.Implementingfault-tolerantservicesusingthestatemachineapproach:Atutorial.ACMComput.Surv.,22(4):299–319,1990.
CastroM,LiskovB.PracticalByzantinefaulttoleranceandproactiverecovery.ACMTransactionsonComputerSystems(TOCS),2002,20(4):398-461.
7月29日,云南省區塊鏈產業發展座談會在北京會議中心隆重舉行。本次座談會由云南省區塊鏈中心運營主體——眾鏈數字經濟產業發展有限公司和中關村金融科技產業發展聯盟聯合舉辦,云南省發改委、中關村金融科.
1900/1/1 0:00:00用戶在以太坊區塊鏈中發現的主要用例是無需中介即可在加密資產之間進行交換的能力。去中心化交易所或DEX是用于此活動的平臺.
1900/1/1 0:00:00收錄于話題 #每日期權播報 播報數據由Greeks.live格致數據實驗室DataLab和Deribit官網提供.
1900/1/1 0:00:00今年三月,藝術家Beeple的一件NFT數字作品《everyday》拍出了6935萬美元的天價,吸引了很多人的關注.
1900/1/1 0:00:00據數據統計,2021年第三季度共發生了11起重大DeFi盜竊事故,其中有5起屬于跨鏈橋資產盜竊事故.
1900/1/1 0:00:00NFT的火熱從未熄滅,之前,支付寶推出一系列的NFT作品,現在LV、保潔等知名品牌陸陸續續加入這個行列;奧迪攜手藝術家程然Chengran創作了NFT藝術作品《幻想高速》.
1900/1/1 0:00:00


