






 BTC/HKD-0.53%
BTC/HKD-0.53% ETH/HKD-0.58%
ETH/HKD-0.58% LTC/HKD-0.33%
LTC/HKD-0.33% DOT/HKD+0.69%
DOT/HKD+0.69% ADA/HKD+0.78%
ADA/HKD+0.78% SOL/HKD+2.96%
SOL/HKD+2.96% XRP/HKD+0.18%
XRP/HKD+0.18% DOGE/US+0.12%
DOGE/US+0.12%在數據時代,廣告的投放效果評估往往會產生很多的問題。而歸因分析要解決的問題就是廣告效果的產生,其功勞應該如何合理的分配給哪些渠道。

一、什么是歸因分析?
在復雜的數據時代,我們每天都會面臨產生產生的大量的數據以及用戶復雜的消費行為路徑,特別是在互聯網廣告行業,在廣告投放的效果評估上,往往會產生一系列的問題:
哪些營銷渠道促成了銷售?他們的貢獻率分別是多少?而這些貢獻的背后,是源自于怎樣的用戶行為路徑而產生的?如何使用歸因分析得到的結論,指導我們選擇轉化率更高的渠道組合?歸因分析要解決的問題就是廣告效果的產生,其功勞應該如何合理的分配給哪些渠道。
你可能第一反應就是:當然是我點了哪個廣告,然后進去商品詳情頁產生了購買以后,這個功勞就全部歸功于這個廣告呀!
沒有錯,這也是當今最流行的分析方法,最簡單粗暴的單渠道歸因模型——這種方法通常將銷售轉化歸功于消費者第一次或者最后一次接觸的渠道。但是顯然,這是一個不夠嚴謹和準確的分析方法。
舉個例子:
小陳同學在手機上看到了朋友圈廣告發布了最新的蘋果手機,午休的時候刷抖音看到了有網紅在評測最新的蘋果手機,下班在地鐵上刷朋友圈的時候發現已經有小伙伴收到手機在曬圖了,于是喝了一杯江小白壯壯膽回家跟老婆申請經費,最后老婆批準了讓他去京東買,有保障。那么請問,朋友圈廣告、抖音、好友朋友圈、京東各個渠道對這次成交分別貢獻了多少價值?——太難了,筆者也不知道
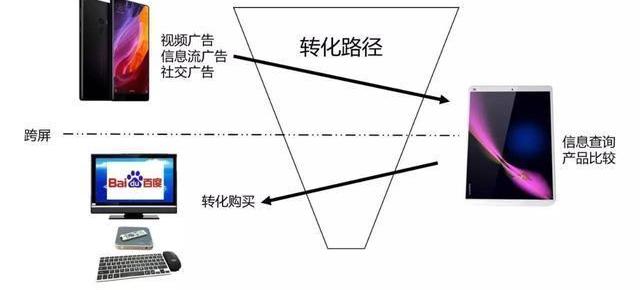
再舉個例子:
下圖是某電商用戶行為序列圖示,各字母代表的含義是D-廣告位,Q-商品詳情頁,D-推薦位,M-購買商品。那么請問,Da、Db、Dc這三種廣告位對這次用戶購買行為的貢獻率分別是多少?這個問題相對簡單點,等你看完文章自然就懂了!
我們發現,現實情況往往是很復雜的多渠道投放,在衡量其貢獻價值以及做組合渠道投放力度的分配時,只依靠單渠道歸因分析得到的結果和指導是不科學的,于是引入了多渠道歸因分析的方法。當然,多渠道歸因分析也不是萬能的,使用怎樣的分析模型最終還是取決于業務本身的特性以及考慮投入其中的成本。
處于盈利的ETH地址數創4個月新高:金色財經報道,Glassnode數據顯示,處于盈利的ETH地址數剛剛達到51,798,806個,創4個月新高。[2023/1/15 11:12:23]
二、幾種常見的歸因模型
1.末次互動模型
也稱,最后點擊模型——最后一次互動的渠道獲得100%的功勞,這是最簡單、直接,也是應用最為廣泛的歸因模型。

優點:首先它是最容易測量的歸因模型,在分析計方面不容易發生錯誤。另外由于大部分追蹤的cookie存活期只有30-90天(淘寶廣告的計算周期最長只有15天),對于顧客的行為路徑、周期比較長的場景,在做歸因分析的時候可能就會發生數據的丟失,而對于末次互動模型,這個數據跟蹤周期就不是那么特別重要了。
弊端:這種模型的弊端也是比較明顯,比如客戶是從收藏夾進入商品詳情頁然后形成了成交的,按照末次歸因模型就會把100%的功勞都歸功于收藏夾。但是真實的用戶行為路徑更接近于產生興趣、信任、購買意向、信息對比等各種環節,這些都是其他渠道的功勞,在這個模型中則無法統計進來,而末次渠道的功勞評估會被大幅高估。
適用于:轉化路徑少、周期短的業務,或者就是起臨門一腳作用的廣告,為了吸引客戶購買,點擊直接落地到商品詳情頁。
2.末次非直接點擊互動模型
上面講到的末次互動模型的弊端是數據分析的準確性受到了大量的”直接流量”所誤導,所以對于末次非直接點擊模型,在排除掉直接流量后會得到稍微準確一點的分析結果。
在營銷分析里,直接流量通常被定義為手動輸入URL的訪客流量。然而,現實是市場上的所有分析工具都把沒有來源頁的流量視為直接流量。比如:文章里沒有加跟蹤代碼的鏈接、用戶直接復制粘貼URL訪問等等
從上面的案例中,我們可以想象,用戶是從淘寶收藏夾里點了一個商品然后進行了購買,但是實際上他可能是點了淘寶直通車后把這個商品加入到收藏夾的,那么在末次非直接點擊互動模型里,我們就可以把這個功勞歸功于淘寶直通車。
持有100枚以上ETH硬幣的地址數量達到14個月高點:金色財經報道,據Glassnode數據,持有100枚以上ETH硬幣的地址數量剛剛達到 44,921 的 14 個月高點。[2022/7/9 2:01:50]
適用于:如果你的公司認為,你們業務的直接流量大部分都被來自于被其他渠道吸引的客戶,需要排除掉直接流量,那么這種模型會很適合你們。
3.末次渠道互動模型
末次渠道互動模型會將100%的功勞歸于客戶在轉化前,最后一次點擊的廣告渠道。需要注意這里的”末次互動”是指任何你要測量的轉化目標之前的最后一次互動,轉化目標可能是銷售線索、銷售機會建立或者其他你可以自定義的目標。
優點:這種模式的優點是通常跟各渠道的標準一致,如FacebookInsight使用末次Facebook互動模型,谷歌廣告分析用的是末次谷歌廣告互動模型等等。
弊端:很明顯當你在多渠道同時投放的時候,會發生一個客戶在第一天點了Facebook的廣告,然后在第二天又點擊了谷歌廣告,最后并發生了轉化,那么在末次渠道模型中,Facebook和谷歌都會把這次轉化的100%功勞分別歸到自己的渠道上。這就導致各個部門的數據都看起來挺好的,各個渠道都高估了自己影響力,而實際效果則可能是折半,如果單獨使用這些歸因模型并且把他們整合到一個報告中,你可能會得到”翻倍甚至三倍”的轉化數據。
適用于:單一渠道,或者已知某個渠道的價值特別大。
4.首次互動模型
首次互動的渠道獲得100%的功勞。
如果,末次互動是認為,不管你之前有多少次互動,沒有最后一次就沒有成交。那么首次互動就是認為,沒有我第一次的互動,你們剩下的渠道連互動都不會產生。
換句話說,首次互動模型更加強調的是驅動用戶認知的、位于轉化漏斗最頂端的渠道。
優點:是一種容易實施的單觸點模型弊端:受限于數據跟蹤周期,對于用戶路徑長、周期長的用戶行為可能無法采集真正的首次互動。適用于:這種模型適用于沒什么品牌知名度的公司,關注能給他們帶來客戶的最初的渠道,對于擴展市場很有幫助的渠道。
5.線性歸因模型
NerveNetwork 2022年Q1已部署4個跨鏈橋接:金色財經消息,去中心化資產跨鏈網絡NerveNetwork發推稱,在2022年第一季已部署4個跨鏈橋接。目前NerveNetwork TVL已經達到35,002,737.29美元。[2022/3/27 14:19:51]
對于路徑上所有的渠道,平等地分配他們的貢獻權重。
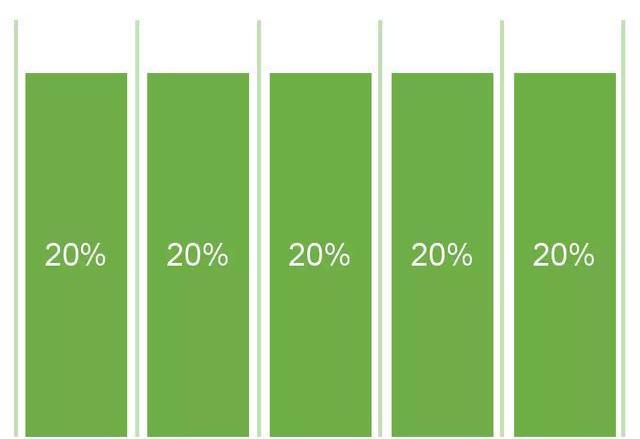
線性歸因是多觸點歸因模型中的一種,也是最簡單的一種,他將功勞平均分配給用戶路徑中的每一個觸點。
優點:他是一個多觸點歸因模型,可以將功勞劃分給轉化漏斗中每個不同階段的營銷渠道。另外,他的計算方法比較簡單,計算過程中的價值系數調整也比較方便。
弊端:很明顯,線性平均劃分的方法不適用于某些渠道價值特別突出的業務。比如,一個客戶在線下某處看到了你的廣告,然后回家再用百度搜索,連續三天都通過百度進入了官網,并在第四天成交。那么按照線性歸因模型,百度會分配到75%的權重,而線下某處的廣告得到了25%的權重,這很顯然并沒有給到線下廣告足夠的權重。
適用于:根據線性歸因模型的特點,他更適用于企業期望在整個銷售周期內保持與客戶的聯系,并維持品牌認知度的公司。在這種情況下,各個渠道在客戶的考慮過程中,都起到相同的促進作用。
6.時間衰減歸因模型
對于路徑上的渠道,距離轉化的時間越短的渠道,可以獲得越多的功勞權重。
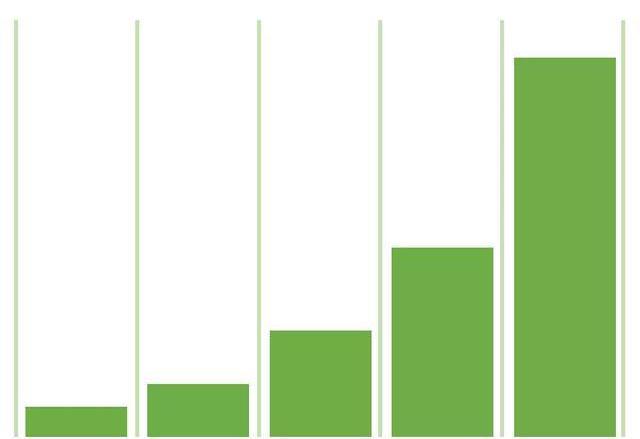
時間衰減歸因模型基于一種假設,他認為觸點越接近轉化,對轉化的影響力就越大。這種模型基于一個指數衰減的概念,一般默認周期是7天。也就是說,以轉化當天相比,轉化前7天的渠道,能分配50%權重,前14天的渠道分25%的權重,以此類推……
優點:相比線性歸因模型的平均分權重的方式,時間衰減模型讓不同渠道得到了不同的權重分配,當然前提是基于“觸點離轉化越近,對轉化影響力就越大”的前提是準確的情況下,這種模型是相對較合理的。
Telegram“搬磚套利”詐騙最新案例,三用戶被騙834個ETH:據追幣獵人CoinHunter報道,近三日有三名用戶提交丟幣事件反饋稱遭受Telegram“搬磚套利”詐騙。不法分子假借“搬磚套利”的說辭,聲稱1個ETH可以兌換50-100(根據行情調整)個“HT”,從而引導三名用戶將834個ETH轉入詐騙者0xcf7eb5e、0x8e047fc開頭的合約地址中,并返還給用戶虛假“HT”從而騙取用戶資產。據CoinHunter統計,“搬磚套利”騙局詐騙總額已超50000枚ETH,截至報道時騙局仍在持續運轉。[2020/4/21]
弊端:這種假設的問題就是,在漏洞頂部的營銷渠道永遠不會得到一個公平的分數,因為它們總是距離轉化最遠的那個。
適用于:客戶決策周期短、銷售周期短的情況。比如,做短期的促銷,就打了兩天的廣告,那么這兩天的廣告理應獲得較高的權重。
7.基于位置的歸因模型
基于位置的歸因模型,也叫U型歸因模型,它其實是混合使用了首次互動歸因和末次互動歸因的結果。
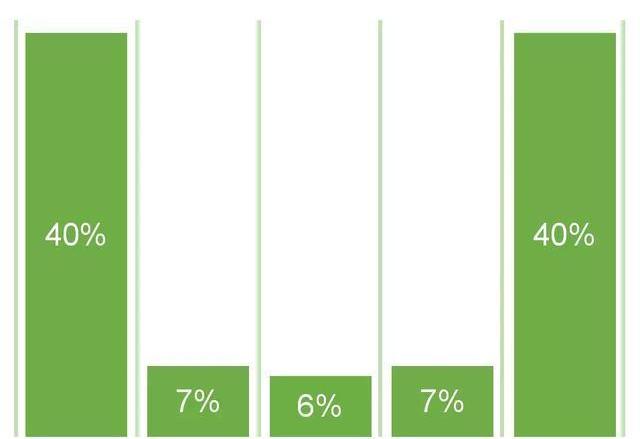
U型歸因模型也是一種多觸點歸因模型,實質上是一種重視最初帶來線索和最終促成成交渠道的模型,一般它會給首次和末次互動渠道各分配40%的權重,給中間的渠道分配20%的權重,也可以根據實際情況來調整這里的比例。
U型歸因模型非常適合那些十分重視線索來源和促成銷售渠道的公司。該模型的缺點則是它不會考慮線索轉化之后的觸點的營銷效果,而這也使得它成為銷售線索報告或者只有銷售線索階段目標的營銷組織的理想歸因模型。
歸因分析模型的計算原理演繹:
以下,我們通過神策數據提供的歸因模式,做一次計算原理的演繹:
下圖是通過神策分析所得到某電商用戶行為序列圖示。在圖示中,各字母代表的含義是D-廣告位、Q-商品詳情頁、D-推薦位、M-購買商品。目標轉化事件是“購買商品”,為了更好地“配對”,運營人員將M1與Q1設置了屬性關聯,同樣將M2與Q2進行關聯。
該場景中,發生了兩次購買行為,神策分析進行歸因時會進行兩輪計算,產生計算結果。
動態 | 24個ICO項目共籌集了28億美元 交易量卻幾乎為零:據cointelligence消息,根據加密貨幣研究員Andrew Tar的一份研究顯示,有24個ICO項目一共籌集了28億美元的資金,交易量卻幾乎為零,許多代幣的流通量不到總量的1%。[2018/11/27]
第一輪計算:
第一步,從M1開始向前遍歷尋找Q1以及離Q1最近發生的廣告瀏覽。
如圖所示,不難得到結果M1=。
第二步,我們帶入分析模型中,進行功勞的分配。運營人員選擇“位置歸因”的分析模型,根據“位置歸因”的計算邏輯,第一個“待歸因事件”和最后一個“待歸因事件”各占40%,中間平分20%。
第一輪我們得到結果:Dc=0.4;Dc=0.2;Da=0.4
第二輪計算:
從M2開始向前遍歷尋找Q2以及離Q2最近發生的廣告瀏覽。
這里值得強調的是,即使第一輪中計算過該廣告,在本輪計算時依然會參與到計算中,因為經常會出現一個廣告位同時推薦多個商品的情況。
我們不難得到結論,M2=。基于這個結論,我們通過“位置歸因”得到結果:Dc=0.5;Db=0.5。
經過兩輪計算,我們得出結論:Dc=1.1;Da=0.4;Db=0.5,則廣告位c的貢獻最大、廣告位b貢獻次之,廣告位a的貢獻最小。
8.馬爾科夫鏈
馬爾科夫鏈模型來自于數學家AndrewMarkov所定義的一種特殊的有序列,馬爾科夫鏈(MarkovChain),描述了一種狀態序列,其每個狀態值取決于前面有限個狀態,馬爾科夫鏈是具有馬爾科夫性質的隨機變量的一個數列。
馬爾科夫鏈思時間、狀態都是離散的馬爾科夫過程,是將來發生的事情,和過去的經理沒有任何關系。通俗的講:今天的事情只取決于昨天,而明天的事情只取決于今天。
谷歌的PageRank,就是利用了馬爾科夫模型。假設有A,B,C三個網頁,A鏈向B,B鏈上C。那么C分到的PR權重只由B決定,和A沒有任何關系。如果互聯網上所有的網頁不斷地重復計算PR,很容易可以想到這個PR值最后會收斂,并且區域一個穩定的值,這也就是為什么它會被谷歌用來確定網頁等級。
回到歸因模型上,馬爾科夫鏈模型實質就是:訪客下一次訪問某個渠道的概率,取決于這次訪問的渠道。
歸因模型的選擇,很大程度上決定轉化率計算結果,像前面講的首次互動、末次互動等模型,實際上需要人工來分配規則的算法,顯然它并不是一種“智能化”的模型選擇。而且因為各個推廣渠道的屬性和目的不同,我們也無法脫離用戶整個的轉化路徑來單獨進行計算。因此,馬爾科夫鏈歸因模型實質上是一種以數據驅動的(Data-Driven)、更準確的歸因算法。
馬爾科夫鏈歸因模型適用于渠道多、數量大、有建模分析能力的公司。
那么具體馬爾科夫鏈怎么玩?
如果將各推廣渠道視為系統狀態,推廣渠道之間的轉化視為系統狀態之間的轉化,可以用馬爾科夫鏈表示用戶轉化路徑。
馬爾科夫鏈表示系統在t+1時間的狀態只與系統在t時間的狀態有關系,與系統在t-1,t-2,…,t0時間的狀態無關,平穩馬爾科夫鏈的轉化矩陣可以用最大似然估計,也就是統計各狀態之間的轉化概率計算得到。用馬爾科夫鏈圖定義渠道推廣歸因模型:
狀態集合,定義為banner,text,keyword,link,video,mobile,unknown7種推廣類型加上start,,conversion3種系統狀態。
穩定狀態下的轉化矩陣,通過某公司web網站20天的原始click數據計算的得到如下狀態轉化矩陣。
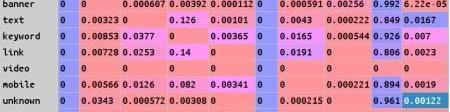
利用該轉化矩陣來構造有向圖,通過計算從節點start到節點conversion的所有非重復路徑的累乘權重系數之和來計算移除效應系數4、通過移除效應系數,計算各個狀態的轉化貢獻值
什么是移除效應?
渠道的移除效應定義為:移除該狀態之后,在start狀態開始到conversion狀態之間所有路徑上概率之和的變化值。通過計算各個渠道的移除效應系數,根據移除效應系數在總的系數之和之中的比例得到渠道貢獻值。移除效應實際上反映的是移除該渠道之后系統整體轉化率的下降程度。
我們可以把上面的案例簡化一下,嘗試具體計算下移除效應和各渠道的轉化貢獻值:
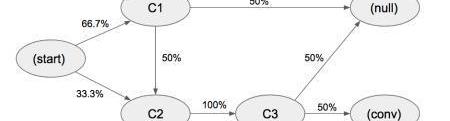
假設簡化后的狀態集是{C1,C2,C3},各路徑上代表狀態間轉化的概率。
在以上系統中,總體的轉化率==33.3%。

當我們嘗試移除節點C1。
移除節點C1后,整體轉化率=0.333*0.1*0.5=16.7%,所以C1節點的移除效應系數=1-0.167/0.333=0.5同理可計算節點C2和C3的移除效應分別是1和1通過移除效應系數計算得到轉化貢獻值:C1:0.5/(0.5+1+1)=0.2C2:1/(0.5+1+1)=0.4C3:1/(0.5+1+1)=0.4
三、如何選擇歸因模型
從上面這么多種歸因模型來看,我們大概可以把他們分成2類:
基于規則的:預先為渠道設置了固定的權重值,他的好處是計算簡單、數據容易合并、渠道之間互不影響,當然你也可以根據實際需要去調整他們的權重配比。
基于算法的:每個渠道的權重值不一樣,會根據算法和時間,不同渠道的權重值會發生變化。
在選擇用何種歸因模型之前,我們應該先想清楚業務模式!
如果是新品牌、新產品推廣,企業應該給予能給我們帶來更多新用戶的渠道足夠的權重,那么我們應該選擇首次互動模型;如果是投放了單一的競價渠道,那么我們應該選取末次互動歸因模型或者渠道互動歸因模型;如果公司很在乎線索來源和促成銷售渠道,那么我們應該選擇U型歸因模型;如果公司的渠道多、數據量大,并且由永久用戶標識,基于算法的歸因模型能夠為營銷分析提供巨大的幫助;……總的來說,沒有完美的歸因模型。任何模型都存在他的局限性和不足,如何有效地結合客觀數據與主觀推測,是用好歸因模型的重要能力前提。
四、還有哪些有趣的歸因模型?
這里拋出一個有趣的問題,大家可以通過思考他背后的分析邏輯,嘗試一下如何應用到歸因模型中:
小陳和小盧同學準備吃午餐,小陳帶了3塊蛋糕,小盧帶了5塊蛋糕。這時,有一個路人路過,路人餓了,于是他們約路人一起吃午飯,路人接受了邀約。小陳、小盧和路人3個人把8塊蛋糕全部吃完了,吃完飯后,路人感謝他們的午餐,于是給了他們8個金幣,然后離去。小陳和小盧為這8個金幣的分配展開了爭執。小盧說:我帶了5塊蛋糕,理應我得5個金幣,你得3個金幣。小陳不同意:既然我們一起吃這8塊蛋糕,理應平分這8個金幣。為此他們找到了公正的夏普里。夏普里說:公正的分發是,小陳你應當得到1個金幣,你的好朋友小盧應該得到7個金幣。經過夏普里的解釋,小陳和小盧認為很有道理,愉快地接受了這種分金幣的方案。請問,夏普里是怎樣分析得到1:7這樣的分配的呢?
本文由@WINTER原創發布于人人都是產品經理。未經許可,禁止轉載
題圖來自Unsplash,基于CC0協議
在社會生活中,直面生死的,便是飲食。沒有食物,人類將難以生存。在幾千年的歷史中,中國古人早就對吃這一項有著獨到的研究。如何吃好吃飽,總結而言,便是七件事“柴、米、油、鹽、醬、醋、茶”.
1900/1/1 0:00:00公鏈治理一直是區塊鏈公鏈行業一直難以解決的難點,一方面部分公鏈都在探索完全去中心化治理,另一方面還有一部分公鏈也在探索人治+有限去中心化治理,雖然雙方都在積極的唱好各自的公鏈治理模式.
1900/1/1 0:00:00還記得中本聰在比特幣創世區塊中留下的那句話嗎?“TheTimes03/Jan/2009Chancelloronbrinkofsecondbailoutforbanks.”(2009年1月3日.
1900/1/1 0:00:00唐代是中國古代極為強盛的朝代,、經濟、文化都有極為豐富的成果。單從商品經濟而言,唐代的蘇州夜市已經十分繁華,詩云“夜市賣菱藕,春船載綺羅.
1900/1/1 0:00:00上周,我們跟大家分享了一建建筑的知識點盤點,并且在文末的評論點贊中,呼聲最高的是經濟實務,那么今天建工社微課程就帶大家看看一建經濟我們在學習中都有哪些注意事項: 一建經濟復習側重點 ①《經濟》科.
1900/1/1 0:00:002011年,RonyAbovitz和團隊創立了MagicLeap公司,而后獲得了30億美元的巨額融資,又親眼目睹了整個VR行業的興起和衰落。9年過去了,這家獨角獸公司還是被迫轉型了.
1900/1/1 0:00:00


