






 BTC/HKD-0.02%
BTC/HKD-0.02% ETH/HKD+0.4%
ETH/HKD+0.4% LTC/HKD+0.81%
LTC/HKD+0.81% DOT/HKD+1.75%
DOT/HKD+1.75% ADA/HKD-0.52%
ADA/HKD-0.52% SOL/HKD+0.12%
SOL/HKD+0.12% XRP/HKD+0.19%
XRP/HKD+0.19% DOGE/US+0.77%
DOGE/US+0.77%作者:宋嘉吉孫爽
摘要
ChatGPT發布后不久,Meta就開源了類GPT大語言模型LLaMA,此后,Alpaca、Vicuna、Koala等多個大模型誕生,它們以遠低于ChatGPT的模型規模和成本,實現了令人矚目的性能,引發業內人士擔憂“谷歌和OpenAI都沒有護城河,大模型門檻正被開源踏破,不合作就會被取代”。資本市場也在關注大模型未來競爭格局如何,模型小了是否不再需要大量算力,數據在其中又扮演了什么角色?……本報告試圖分析這波開源大語言模型風潮的共同點,回顧開源標桿Linux的發展史,回答這些問題。
共同點一:始于開源。開源≠免費,開源的商業模式至少包括:1、靠服務變現。曾上市、后被IBM收購的Linux企業服務公司紅帽即是一例。企業為了更穩定和及時的技術支持,愿意付費。2、靠授權費變現。安卓開源,但谷歌向歐盟使用安卓谷歌套件的廠商收取許可費即是一例。3、許可證、標準和能力評價體系的發展,是開源大模型商用程度深化的催化劑。這波開源大模型采用的許可證協議主要是Apache2.0和MIT,它們不禁止商用,并且不禁止用戶修改模型后閉源,這有助于公司應用此類大模型。
共同點二:參數少、小型化。相較于GPT3+千億參數超大模型,這波開源大模型的參數量普遍在十億至百億級別。目前尚沒有一套系統的大模型性能評價體系,其中僅部分任務有公信力較強的評分標準。開源大模型中,Vicuna的能力也較強,在部分任務能達到92%GPT4的效果。總體來說,OpenAIGPT系仍一騎絕塵,但訓練成本高,難復現。而開源大模型借助更大標識符訓練數據集、DeepSpeed、RLHF等方式,實現低訓練成本和高性能,超大模型以下大模型的壁壘正在消失。
共同點三:數據集重視人類指令,并走向商用。ChatGPT相較于GPT3效果大幅提升的重要因素是使用了RLHF,即在訓練中,使用人類生成的答案和對AI生成內容的排序,來讓AI“對齊”人類偏好。LLaMA沒有使用指令微調,但LLaMA之后的大量大模型使用并開源了指令數據集,并且逐步探索自建指令數據集,而非使用有商用限制的OpenAI的,進一步降低了復現GPT的門檻,擴展了商用可用性。
接下來怎么看開源大模型?站在開源大模型浪潮中,我們注意到兩個趨勢:1)與多模態融合,清華大學的VisualGLM-6B即是著名開源語言模型ChatGLM的多模態升級版,我們認為,其可基于消費級顯卡在本地部署的特性是大勢所趨。2)開源模型+邊緣計算推動AI商用落地,哈爾濱大學的中文醫療問診模型“華駝”以及在跨境電商的使用就是案例。
投資建議:我們認為,對大模型的看法應該分時、分層看待。1、短期內,OpenAI的GPT系超大模型仍然超越眾開源大模型,因此,應當重點關注與其在股權和產品上深度合作的微軟、能獲得ChatGPTiosApp收益分成的蘋果,以及超大模型的算力服務商英偉達等;2、中長期來看,如果部分開源大模型能力被進一步驗證,則應用將快速鋪開,大模型對算力將形成正循環;3、其他:邊緣算力、大數據公司和開源大模型服務商業態也值得關注。建議關注:1)光模塊服務商:中際旭創、新易盛、天孚通信、源杰科技;2)智能模組服務商:美格智能、廣和通;3)邊緣IDC服務商:龍宇股份、網宿科技;4)AIoT通信芯片及設備廠商:中興通訊、紫光股份、銳捷網絡、菲菱科思、工業富聯、翱捷科技、初靈信息;5)應用端標的:愷英網絡、神州泰岳、佳訊飛鴻、中科金財等。
風險提示:倫理風險、市場競爭風險、政策法律監管風險。



Findora公布審核代碼庫結果并計劃于2021Q1發布開源代碼:據官方消息,Findora與一家美國上市的軟件行業安全審計公司合作,對方對Findora即將開源代碼庫進行分析檢測。 針對安全性和風險的初步審核結果顯示代碼庫的結構設計和抗攻擊性等方面均表現非常出色,在各個方面均達到或者超出行業內認可的標準。
審核一共掃描和分析了超過9800多個文件,該審計報告指出Findora代碼庫在安全薄弱程度方面的評價結果是“極低”。在完成全面的安全審核后,Findora將在未來公布開源時間表,從2021年第一季度開始逐步發布其開源代碼。
Findora旨在成為金融服務行業的粘合劑-即實現任何性質的資產并應對支持和統一各種加密貨幣和傳統資產的必要挑戰-安全仍然是我們的首要任務,并且是實現廣泛采用并建立全球信任這一目標的基礎。進行端到端的第三方安全審核并取得優異的結果是朝此方向邁出的兩個重要步驟。[2021/1/5 16:27:50]
一、引言
一篇報道引發了公眾對開源大語言模型的強烈關注。
1.1“谷歌和OpenAI都沒有護城河,大模型門檻正被開源踏破”
“除非谷歌和OpenAI改變態度,選擇和開源社區合作,否則將被后者替代”,據彭博和SemiAnalysis報道,4月初,谷歌工程師LukeSernau發文稱,在人工智能大語言模型賽道,谷歌和ChatGPT的推出方OpenAI都沒有護城河,開源社區正在贏得競賽。
這一論調讓公眾對“年初Meta開源大模型LLaMA后,大模型大量出現”現象的關注推向了高潮,資本市場也在關注大公司閉源超大模型和開源大模型誰能贏得競爭,在“模型”“算力”“數據”三大關鍵要素中,大模型未來競爭格局如何,模型小了是否就不再需要大量算力,數據在其中又扮演了什么角色?……本報告試圖剖析這波開源大模型風潮的共同點,回顧開源標桿Linux的發展史,回答以上問題,展望大模型的未來。

1.2開源大模型集中出現,堪稱風潮
2月24日,Meta發布LLaMA開源大模型,此后,市場集中涌現出一批大模型,大致可以分為三類。
1.2.1“LLaMA系”:表現好,但商用化程度低
LLaMA包括四個不同的參數版本,不支持商用,指令數據集基于OpenAI,模型表現可與GPT-3持平或優于GPT-3。其中,70億和130億參數版擁有包含1萬億個標識符的預訓練數據集;330億和650億參數版擁有包含1.4萬億個標識符的預訓練數據集。在與GPT-3的對比中,LLaMA-70億參數版在常識推理任務、零樣本任務、自然問題和閱讀理解中的表現與GPT-3水平相當,而130億參數及更高參數的版本模型在以上領域的表現均優于GPT-3。
LLaMA模型本身沒有使用指令數據集,但考慮到效果優于GPT-3的ChatGPT使用了人類指令數據集,一批開源大模型在LLaMA模型基礎上,使用了OpenAI指令數據集來優化模型的表現,包括Alpaca、GPT4All、Vicuna、Koala、OpenAssistant和HuggingChat。由于OpenAI指令數據集不可商用,因此這批基于LLaMA的開源大模型也都不可商用。
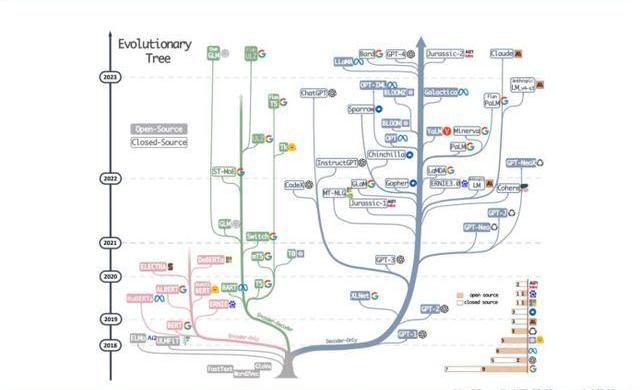
1.2.2Dolly2.0、RedPajama、StableLM等:商用化程度高
這些大模型沒有使用OpenAI指令數據集,因此可以商用,但大多數還在持續開發中。
1.2.3中文雙子星:ChatGLM-6B和MOSS
ChatGLM-6B和MOSS分別由清華大學和復旦大學相關研究團體推出,在中文社區知名度較高。
現場 | 周平:國內將政府標準與開源連在一起 促進區塊鏈標準站在行業發展最前沿:金色財經現場報道,在2019網易未來大會“原點·共生”分論壇區塊鏈+實體經濟論壇上,中國電子技術標準化研究院軟件工程與評估中心主任周平作了以“區塊鏈標準化之路”為主題的演講。周平表示,區塊鏈很新,還無法形成國家標準,只能通過團體標準來逐漸應用推動形成國家標準。明年相對應的國家標準會出現,英國在初項提案中共定義110余個術語,經過相對模糊的數據采取簡化或者完全刪除的處理方式,目前共定義84個術語。區塊鏈行業標準的作用,能夠支撐核心關鍵技術創新與發展,另一個作用是培育行業的發展。目前國內政府標準與開源連在一起,來促進區塊鏈標準能夠站在行業發展的最前沿。[2019/11/23]
這批模型還具有一些共同點,報告將在下文詳述。
二、共同點一:始于開源
這波風潮中,不管是模型本身,還是模型所使用的數據集,它們首要的共同點是“開源”。
2.1為什么要開源?
市場對開源大模型的重要問題是,為什么要開源,這是否會損傷大模型行業的商業模式。我們梳理了部分大模型對開源原因的自述,總結如下。
2.1.1模型視角:防止大公司壟斷,破除商業禁用限制
為了使人工智能研究民主化,彌合開放模型和封閉模型之間的質量差距,破除商業化禁用限制,開源大模型的蓬勃發展有望促進以上目標。
2.1.2數據視角:保護企業機密,使定制化數據訓練成為可能
保障數據隱私,允許企業定制化開發。對于許多行業而言,數據是企業的命脈,大模型的開源使得企業可以將自己的數據集在大模型上進行訓練,同時做到對數據的控制,保護企業數據隱私。同時,開源大模型允許企業的開發人員在模型的基礎上進行定制化開發,定向訓練數據,也可以針對某些主題進行過濾,減少模型體量和數據的訓練成本。
2.1.3算力視角:降低算力成本,使大模型的使用“普惠化”
開源大模型節省了訓練階段的算力消耗,為企業降低算力成本,推動大模型使用“普惠化”。算力總需求=場景數*單場景算力需求。在大模型的訓練和使用中,算力消耗分為兩部分場景,即訓練成本消耗及推理成本消耗。
就訓練成本而言,大模型的訓練成本高,普通企業的算力資源難以承受,而開源大模型主要節省了企業預訓練階段的算力。但由于不同垂類的訓練場景更加豐富,所以整體訓練需求是增長的。
就推理成本而言,大模型在參數體量龐大的情況下,其推理成本也很高,普通公司難以維持其日常開銷,因此,降低模型參數體量可進而降低企業在使用模型時的推理成本。
2.2開源,需要什么土壤?
開源大模型的蓬勃發展并非沒有先例,全球規模最大的開源軟件項目——Linux有類似的故事。研究Linux的發展史,對展望開源大模型的未來,有借鑒意義。
2.2.1從開源標桿Linux說開去
Linux是一款基于GNU通用公共許可證發布的免費開源操作系統。所有人都能運行、研究、分享和修改這個軟件。經過修改后的代碼還能重新分發,甚至出售,但必須基于同一個許可證。而諸如Unix和Windows等傳統操作系統是鎖定供應商、以原樣交付且無法修改的專有系統。
許多全球規模最大的行業和企業都仰賴于Linux。時至今日,從維基百科等知識共享網站,到紐約證券交易所,再到運行安卓的移動設備,Linux無處不在。當前,Linux不僅是公共互聯網服務器上最常用的操作系統,還是速度排名前500的超級電腦上使用的唯一一款操作系統。
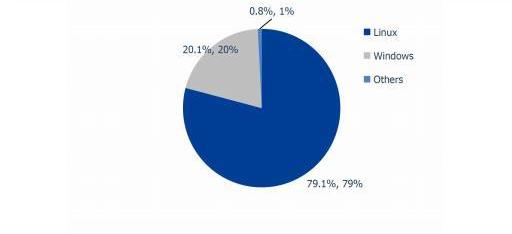
服務器市場,Linux市占率已經遠超操作系統“鼻祖”Unix,“Linux時刻”發生。以中國市場為例,根據賽迪顧問數據,按照裝機量統計,在服務器架構上,Linux是市場主流,占據絕對領先地位,市場占有率達到79.1%。Windows市場占有率降至20.1%,Unix市場占有率僅剩0.8%。
動態 | 新開源標準WebLN將簡化閃電網絡支付:據coindesk報道,由開發人員William O’Beirne撰寫的開源WebLN標準被用于簡化閃電網絡支付。該新標準現在已被閃電錢包Lightning Joule和Bluewallet,以及像Lightning Spin這樣的應用程序用來簡化用戶進行付款所需的步驟數量。[2019/3/26]
2.2.2Linux并非一己之作,借力于社區身后的開源歷史
Unix開源過,為Linux提供了火種
Unix,現代操作系統的鼻祖。操作系統是指直接管理系統硬件和資源的軟件,它位于應用與硬件之間,負責在所有軟件與相關的物理資源之間建立連接。而Unix被許多觀點認為是現代操作系統的鼻祖。
Unix曾開源。世界上第一臺通用型計算機誕生于1946年,而Unix開發于1969年。在長達十年的時間中,UNIX擁有者AT&T公司以低廉甚至免費的許可將Unix源碼授權給學術機構做研究或教學之用,許多機構在此源碼基礎上加以擴展和改進,形成了所謂的“Unix變種”。后來AT&T意識到了Unix的商業價值,不再將Unix源碼授權給學術機構,并對之前的Unix及其變種聲明了著作權權利
Unix回歸閉源之后太貴,促成了Linux的開發
Linux由LinuxTorvalds于1991年設計推出,當時他還在讀大學,認為當時流行的商業操作系統Unix太貴了,于是基于類Unix操作系統Minix開發出了Linux,并將其開放給像自己這樣負擔不起的團隊。
僅用于教學的Minix,啟發了Linux的開發
在AT&T將源碼私有化后,荷蘭阿姆斯特丹自由大學教授塔能鮑姆為了能在課堂上教授學生操作系統運作的實務細節,決定在不使用任何AT&T的源碼前提下,自行開發與UNIX相容的作業系統,以避免版權上的爭議。他以小型UNIX之意,將它稱為MINIX。第一版MINIX于1987年釋出,只需要購買它的磁片,就能使用。在Linux系統還沒有自己的原生檔案系統之前,曾采用Minix的檔案系統。
開源社區、許可證與標準助力
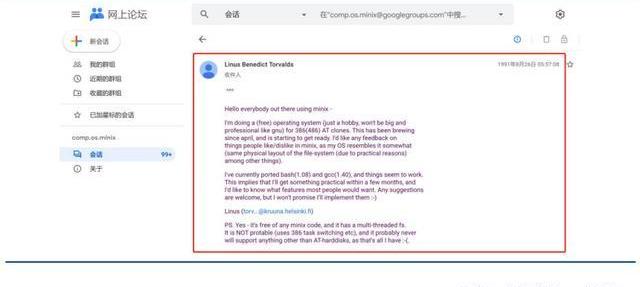
從開始就開源。1991年8月,Linux創始人LinusTorvalds將Linux發到MinixUsenet新聞組。隨后他將Linux發布到FTP網站上,因為他想讓更多人一起來開發這個內核。
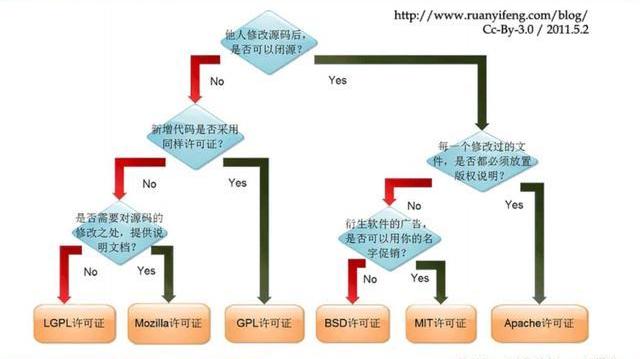
許可證助力生態開枝散葉、生生不息。Linux基于GNUGPL許可證模式。GPL許可證賦予“自由軟件”賦予用戶的四種自由,或稱“Copyleft”:
自由之零:不論目的為何,有“使用”該軟件的自由。
自由之一:有“研究該軟件如何運作”的自由,并且得以“修改”該軟件來符合用戶自身的需求。可訪問源代碼是此項自由的前提。
自由之二:有“分發軟件副本”的自由,所以每個人都可以借由散布自由軟件來敦親睦鄰。
自由之三:有將“公布修訂后的版本”的自由,如此一來,整個社群都可以受惠。可訪問源代碼是此項自由的前提。
GPL許可證要求GPL程序的派生作品也要在遵循GPL許可證模式。相反,BSD式等許可證并不禁止派生作品變成專有軟件。GPL是自由軟件和開源軟件的最流行許可證。遵循GPL許可證使得Linux生態能生生不息,不至于走進無法繼續發展的“死胡同”。
標準對內使生態“形散而神不散”,對內擁抱“巨鯨”。
對內統一標準。Linux制定了標準LSB來規范開發,以免各團隊的開發結果差異太大。因此,各Linux衍生開發工具只在套件管理工具和模式等方面有所不同。我們認為,這使得Linux開源社區的發展“形散而神不散”,使Linux生態的發展不至于分崩離析。
動態 | 開源銀行Marble在以太坊主網中引入閃電貸款概念:7月17日消息,開源銀行Marble今日在推特上發布公告,根據公告,Marble推出了一個名為“閃存貸款”的新概念,任何人都可以借用以太幣和ERC-20代幣來利用以太坊區塊鏈的套利機會。為了實現這一目標,Marble開發了一個智能合約,可用于貸方的低風險協議。有了閃電貸款,開發商和交易員就可以輕松地從缺乏流動性的以太坊資產中獲利,而無需動用自己的資金。[2018/7/17]
對外兼容Unix。為了讓Linux能兼容Unix軟件,LinusTorvalds參考POSIX標準修改了Linux,這使得Linux使用率大增。該標準由IEEE于20世紀90年代開發,正是Linux的起步階段,它致力于提高Unix操作系統環境與類Unix操作系統環境下應用程序的可移植性,為Linux的推廣提供了有利環境。
2.3開源了,還怎么賺錢?
市場對“開源”的核心疑問是商業模式。“開源”本身免費,但“開源”作為土壤,“開源社區”孕育出了各種商業模式,從Linux的生態中可以學習到這一點。
2.3.1紅帽公司:服務至上
紅帽公司是Linux生態的領軍企業,超過90%的《財富》500強公司信賴紅帽公司,紅帽作為公司的商業價值巨大。1993年,紅帽成立,1999年,紅帽即在納斯達克上市,紅帽招股書援引IDC的數據稱,截止到1998年所有經授權的新安裝Linux操作系統中,有56%來自紅帽;2012年,紅帽成為第一家收入超過10億美元的開源技術公司;2019年,IBM以約340億美元的價格收購了紅帽。
關于Linux和紅帽的商業模式,就像好奇心日報打的比方,某種意義上,開源的Linux內核像免費、公開的菜譜,紅帽們像餐廳,人們仍然愿意去餐廳品嘗加工好的菜肴和享受貼心的服務。紅帽面向企業提供Linux操作系統及訂閱式服務,主要服務內容包括:1、24*7技術支持;2、與上游社區和硬件廠商合作,支持廣泛的硬件架構,如x86、ARM、IBMPower等;3、持續的漏洞警報、定向指導和自動修復服務;4、跨多個云的部署;5、實時內核修補、安全標準認證等安全防護功能;6、檢測性能異常、構建系統性能綜合視圖,并通過預設調優配置文件應用等。
2.3.2安卓系統:背靠谷歌,靠廣告變現
根據Statcounter數據,截至2023年4月,安卓系統是全球第一手機操作系統,市占率高達69%,遠超第二名。安卓基于Linux內核開發,2005年被谷歌收購。隨后,谷歌以Apache免費開放源代碼許可證的授權方式,發布了安卓的源代碼,使生產商可以快速推出搭載安卓的智能手機,這加速了安卓的普及。
而關于商業模式,安卓手機預裝的諸多服務由谷歌私有產品提供,例如地圖、GooglePlay應用商店、搜索、谷歌郵箱……因此,盡管安卓免費、開源,但谷歌仍能通過其在移動市場“攻城略地”,將用戶流量變現。
谷歌還直接向安卓手機廠商收取授權費,從2018年10月29日開始,使用安卓系統的手機、平板電腦的歐盟廠商使用谷歌應用程序套件,必須向谷歌支付許可費,每臺設備費用最高達40美元。
2.4開源大模型主流許可證支持商用
開源社區已經有GPL、BSD、Apache等知名許可證。大模型方面,我們注意到,2023年2月發布的、引領了大模型開源浪潮的LLaMA禁止商用,僅可用于研究,MetaAI將根據具體情況,授予公務員、社會團體成員、學術人員和行業研究實驗室,訪問該模型的權限。其中,LLaMA的推理代碼基于GPL3.0許可證,這意味著:1)他人修改LLaMA的推理代碼后,不能閉源;2)新增代碼也必須采用GPL許可證。不過,我們注意到,部分開發人員在LLaMA基礎之上開發的變體模型,有不同類型的許可證。例如,基于nanoGPT的LLaMA實現Lit-LLaMA新增了部分模型權重,這部分模型采用的許可證是Apache2.0。
DAV基金會希望將開源的區塊鏈平臺與移動性結合:DAV基金會首席執行官兼創始人Noam Copel表示,他和他的團隊正在嘗試使用區塊鏈為未來的移動生態系統創造一些結締組織。最終的目標是建立一個分散的運輸網絡,使任何數量的公司能夠參與到任何數量的客戶中。就像互聯網一樣,這個網絡上的任何用戶都可以與任何其他用戶進行通信和交易,無論這些用戶是人還是車輛。[2018/3/14]
開源大模型采用的協議主要是Apache2.0和MIT許可證。Alpaca、Vicuna、Dolly、OpenAssistant和MOSS均采用Apache2.0許可證,Koala和GPT4all采用MIT許可證。這兩個許可證均允許商用。但令人惋惜的是,Alpaca、Vicuna、Koala和GPT4all因OpenAI或LLaMA限制無法商用。同時,值得注意的是,Apache2.0和MIT許可證均允許再修改源碼后閉源,公司可以在開源大模型基礎上開發自己的模型,或對公司更有吸引力。
三、共同點二:開源大模型參數少、小型化
“模型參數的大小”與“模型對算力的需求”正相關。
3.1超大模型和大模型分別多大?
預訓練賦予模型基本能力。在自然語言處理中,預訓練是指在特定任務微調之前,將語言模型在大量文本語料庫上訓練,為模型賦予基本的語言理解能力。在預訓練過程中,模型被訓練以根據前面的上下文預測句子中的下一個單詞。這可以通過掩蓋一些輸入中的單詞并要求模型預測它們的方式進行,也可以采用自回歸的方法,即根據句子中的前面單詞預測下一個單詞。
預訓練模型通常包括大量的參數和對應的預訓練數據。2017年谷歌大腦團隊Transformer模型的出現,徹底改變了NLP的面貌,使得模型可以更好地理解和處理語言,提高NLP任務的效果和準確性。
超大模型和大模型分別多大?語言模型的大小是根據其參數量來衡量的,參數量主要描述了神經元之間連接強度的可調值。目前一般大語言模型參數量在幾十到幾百億之間,超過千億參數的我們稱為“超大模型”,例如GPT-3。
3.2GPT系超大模型能力最強,但難復現
大模型的性能評價標準并沒有統一。一個重要原因是大模型生成內容的任務種類多,不同的應用場景和任務可能需要不同的指標和方法去評估模型的表現。其中部分任務可能有公信力較強的評分標準,如機器翻譯中的BLEU,但大部分任務缺乏類似標準。
模糊共識是超大模型性能好。大語言模型目前的發展趨勢是越來越大,原因是大模型在預訓練后就具有較好通用性和穩定性。例如,谷歌團隊的超大模型PaLM,在零樣本和少量樣本測試中均有良好的成績,并且隨著其訓練標識符數量的上升,性能仍能提升。這也不難理解,簡單來說,模型見得多了,自然會的也多了。
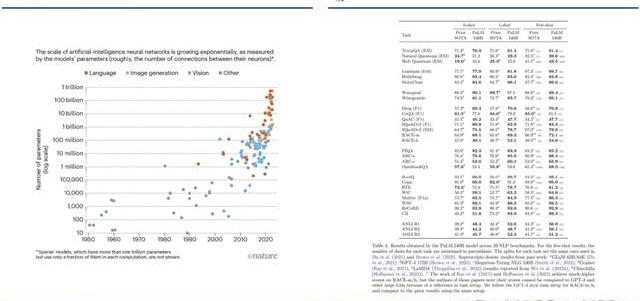
“同行評議”,GPT系大模型“風華絕代”。當前,OpenAIGPT系的超大模型擁有著強大的能力和廣泛的應用,在處理自然語言任務時具有高準確性和強大的表達能力,其在文本生成、問答系統、機器翻譯等多個領域都取得了出色效果,成為了當前自然語言處理領域的標桿之一,被各類大模型當作比較基準。復現ChatGPT的門檻并沒有降低,開源大模型大部分僅在某些方面有較好的表現,整體質量與ChatGPT仍不可比,尚需觀望。

近段時間以來,我們還注意到如下評價體系,評價方法主要包括機器自動評測、人類盲評等,我們重點介紹其中部分及其測評結果,但不論哪種評價體系,GPT系大模型都一騎絕塵。
海外
伯克利大學ChatbotArena借鑒游戲排位賽機制,讓人類對模型兩兩盲評;
開源工具包ZenoBuild,通過HuggingFace或在線API,使用Critique評估多個大模型。
海內
SuperCLUE中文通用大模型綜合性評測基準,嘗試全自動測評大模型;
C-Eval采用1.4萬道涵蓋52個學科的選擇題,評估模型中文能力,類似標準尚需時間和市場的檢驗。
3.2.1Vicuna:利用GPT-4評估
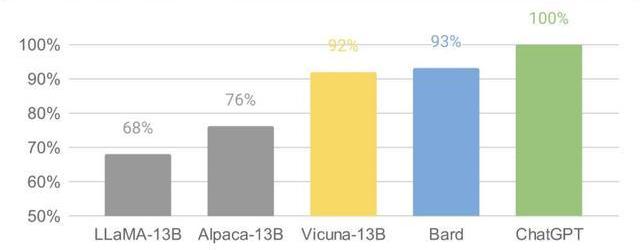
目前大部分開源大模型性能未進行系統評價,更多處在起步試驗階段。在對性能進行評價的開源大模型中,Vicuna的報告中利用GPT-4進行的評估相對較為系統,結果也最令人矚目。
3.2.2ZenoBuild測評:較新,較全面
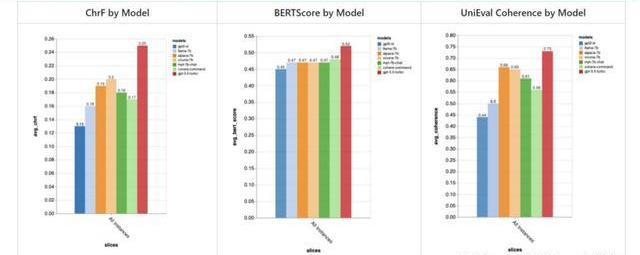
ZenoBuild對GPT-2、LLaMA、Alpaca、Vicuna、MPT-Chat、CohereCommand、ChatGPT七個模型測評,結果與GPT-4評價結果相近。ChatGPT有明顯優勢,Vicuna在開源模型中表現最佳。
3.2.3C-Eval:全面的中文基礎模型評估套件
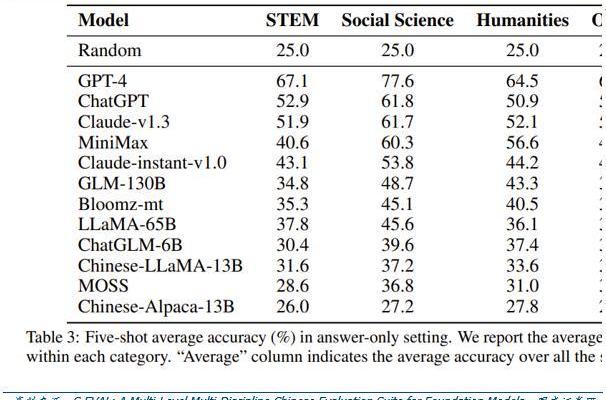
C-Eval評估結果顯示,即便是在中文能力上,GPT-4也是一騎絕塵,但GPT-4也僅能達到67%的正確率,目前大模型的中文處理能力尚有很大提升空間。
3.2.4GPT系超大模型訓練成本高,短期內難復現
ChatGPT所需算力和訓練成本可觀。不考慮與日活高度相關的推理過程所需的算力,僅考慮訓練過程,根據論文《LanguageModelsareFew-ShotLearners》的測算,ChatGPT的上一代GPT-3所需的算力高達3640PF-days,已知單張英偉達A100顯卡的算力約為0.6PFLOPS,則訓練一次GPT-3,大約需要6000張英偉達A100顯卡,如果考慮互聯損失,大約需要上萬張A100,按單張A100芯片價格約為10萬元,則大規模訓練就需要投入約10億元。OpenAI在GPT-3的訓練上花費了超過400萬美元,而為了維持ChatGPT和GPT4的運轉,每個月理論上更高。
3.3開源大模型性價比高,超大模型以下大模型的壁壘正在消失
開源大模型小型化趨勢明顯,參數約為百億級別,成本降低乃題中之義。開源大模型通常具有較少的參數,在設計、訓練和部署上,需要的資源和成本都相對較低。這波開源大模型的參數普遍較小,均在十億~百億級別左右。
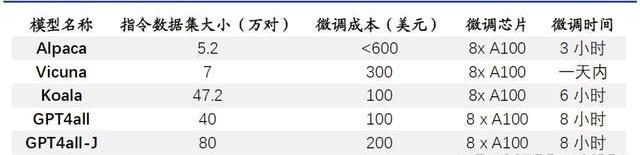
“船小好調頭”,基于已有的開源預訓練模型進行微調也是開源大模型的優勢之一。在預訓練模型基礎上進行微調和優化,以適應不同的任務和應用場景,這種方法不僅可以大大縮短模型的訓練時間和成本,而且還可以提高模型的性能和效率。
更多標識符訓練數據和新技術,讓超大模型以下的大模型壁壘趨于消失。LLaMA被“開源”,讓大家都有了一個可上手的大模型,并且隨著DeepSpeed、RLHF等技術的發展,幾百億的模型可以部署在消費級GPU上。
更多標識符訓練數據可能比更多參數重要:DeepMind發表于2022年3月29日的研究《TrainingCompute-OptimalLargeLanguageModels》向我們揭示了模型大小和訓練數據規模之間的關系:
大模型往往訓練不足,導致大量算力的浪費。
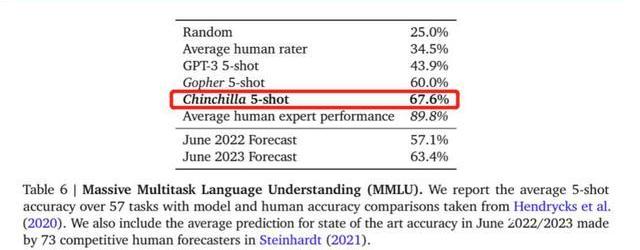
用更小的模型更充分地訓練,能達到比大模型更好的性能。例如DeepMind的Chinchilla,模型僅有700億參數,經過1.4萬億標識符訓練數據集的訓練,在測試中效果優于DeepMind的Gopher和OpenAI的GPT-3。
為了更好地實現模型性能,模型參數量每翻一倍,標識符訓練數據集的規模也應該隨之翻一倍。
更小的模型,也意味著更小的下游微調和推理成本。
DeepSpeed技術:可以顯著減少訓練大模型的時間和成本;
RLHF:可以以較小的標識符訓練量提高模型的性能和準確性。
四、共同點三:開源大模型數據集重視人類指令,并自立門戶
“數據集的大小”也與“模型所需的算力”正相關。
4.1學習ChatGPT方法論,引入人類指令數據集
微調是提升特定性能的捷徑。微調是指在已經預訓練的模型上,使用具有標注數據的特定任務數據集,進一步小規模訓練。微調可以以較小的算力代價,使模型更加適應特定任務的數據和場景,從而提高模型的性能和準確性。目前微調多為指令微調,指令數據集逐漸成為開源大模型的標配。
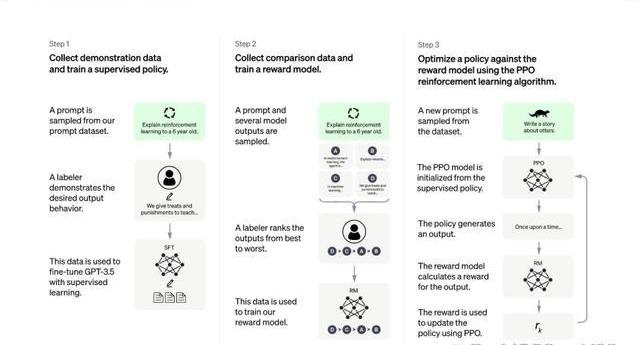
RLHF,是一種新興的微調方法,它使用強化學習技術來訓練語言模型,并依據人類反饋來調整模型的輸出結果。RLHF是ChatGPT早期版本GPT3所不具備的功能,它使得只有13億參數的InstructGPT表現出了比1750億參數GPT-3更好的真實性、無害性和人類指令遵循度,更被標注員認可,同時不會折損GPT-3在學術評估維度上的效果。
RLHF分為三個步驟:1)監督微調:讓標注員回答人類提問,用這一標注數據訓練GPT;2)獎勵模型訓練:讓標注員對機器的回答排序,相較于第一步由標注員直接撰寫回答的生成式標注,排序作為判別式標注的成本更低,用這一標注訓練模型,讓它模擬人類排序;3)無人類標注,用近端策略優化算法微調模型。
這三個步驟對應的數據集的大小分別為1.3萬個、3.3萬個、3.1萬個。
對于具有大量數據和一定算力的公司來說,使用自己的數據進行微調可以展現出模型的特化能力,并且用較小的算力達成接近大模型的效果。如多校聯合開發的Vicuna語言模型,基于Meta的LLaMA-130億參數版模型,對7萬條用戶分享的ChatGPT對話指令微調,部分任務上,達到了92%的GPT4的效果。在通用性和穩定性上無法超過超大模型,但可以通過微調強化其某些方面的能力,性價比要更高,更適合中小公司應用。
4.2數據集走向商用
數據集是語言模型發展的重要基礎和支撐,通常是由公司或組織自主收集、整理或直接購買獲得。相比之下,開源數據集大多由社區或學術界共同維護的,其數據量和種類更加豐富,但可能存在一定的數據質量問題和適用性差異。
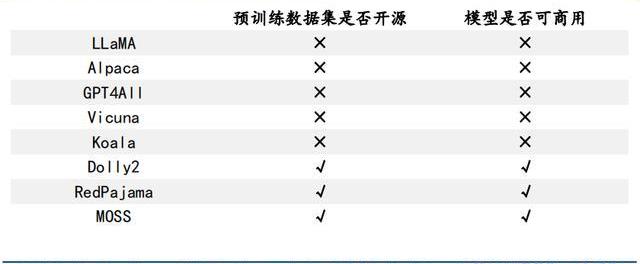
4.2.1預訓練數據集少量可商用
預訓練數據集開源對模型商用至關重要。在后LLaMA時代,開源大模型猶如雨后春筍般涌現,但很快大家便發現由于LLaMA和OpenAI的限制,基于其開發的模型無法商用,為了打破這一局面,Dolly2.0率先出手,“為了解決這個難題,我們開始尋找方法來創建一個新的,未被“污染”的數據集以用于商業用途。”隨后RedPajama和MOSS接踵而至。
4.2.2指令數據集部分可商用
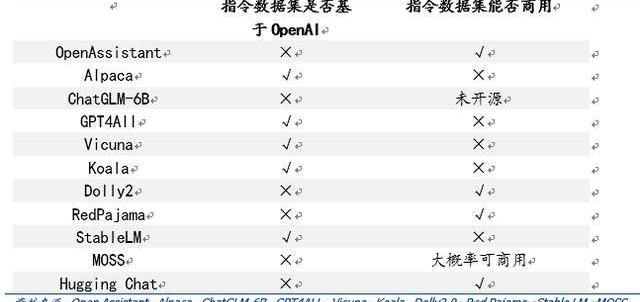
打造開源生態,各取所需。在早期開源項目中,因其指令數據及多來自ChatGPT生成或對話內容,受OpenAI限制無法商用。除去研究用途微調外,目前越來越多模型選擇自己構建指令數據集來繞開這一限制。
指令數據集多樣化,部分模型的指令數據集可商用化。按照上文對此批集中出現的大模型的分類,除去LLaMA、基于LLaMA開發出的模型以及StableLM使用OpenAI的指令數據集外,其余大模型的指令數據集均不基于OpenAI,也因此這些大模型的指令數據集可商用化,這會加快推動使用且重視RLHF訓練范式的此類大模型的更迭與發展。
五、展望
我們注意到開源大模型走向相似的路口。
5.1多模態化:助力通用人工智能發展
多模態開源大模型開始出現,將大模型推向新高潮,助力人類走向通用人工智能。多模態即圖像、聲音、文字等多種模態的融合。多模態模型基于機器學習技術,能夠處理和分析多種輸入類型,可以讓大模型更具有通用性。基于多領域知識,構建統一、跨場景、多任務的模型,推動人類走向通用人工智能時代。
5.1.1ImageBind閃亮登場,用圖像打通6種模態
ImageBind開源大模型可超越單一感官體驗,讓機器擁有“聯想”能力。5月9日,Meta公司宣布開源多模態大模型ImageBind。該模型以圖像為核心,可打通6種模態,包括圖像、溫度、文本、音頻、深度信息、動作捕捉傳感。相關源代碼已托管至GitHub。該團隊表示未來還將加入觸覺、嗅覺、大腦磁共振信號等模態。
從技術上講,ImageBind利用網絡數據,并將其與自然存在的配對數據相結合,以學習單個聯合嵌入空間,使得ImageBind隱式地將文本嵌入與其他模態對齊,從而在沒有顯式語義或文本配對的情況下,能在這些模態上實現零樣本識別功能。
目前ImageBind的典型用例包括:向模型輸入狗叫聲,模型輸出狗的圖片,反之亦可;向模型輸入鳥的圖片和海浪聲,模型輸出鳥在海邊的圖片,反之亦可。
Tags:GPTNIX人工智能GPT價格GPT幣NIX幣是什么幣人工智能技術應用學人工智能后悔死了人工智能考研考哪些科目
全文共2161字,閱讀時間約為3分鐘區塊鏈技術不僅僅是用于加密貨幣交易的系統,它還可以在多個領域得到應用。其中一個廣泛運用區塊鏈技術的場景是數字身份認證.
1900/1/1 0:00:00在其網絡費用恢復到正常水平后,以太坊(ETH)的價格小幅上漲,但仍需要將強大的阻力位轉化為支撐位才能實現更大幅度的上漲.
1900/1/1 0:00:00編者按: 2020年4月,人民銀行公布了首批四個數字人民幣試點地區和一個場景:蘇州、成都、深圳、雄安和北京冬奧會.
1900/1/1 0:00:00注意!2023年秋季福州市臺江區小學一年級招生劃片范圍以及2023年臺江區小學招生工作意見已經發布!一起來看2023年臺江轄區各小學招生劃片范圍.
1900/1/1 0:00:00Layer1 Layer1是其他區塊鏈應用程序構建的基礎架構。它們執行大部分鏈上交易,并作為公共區塊鏈的真相源。傳統的L1區塊鏈往往會面臨交易速度慢、可擴展性低和高Gas費等問題.
1900/1/1 0:00:00幣安:支持以太坊合并計劃,目前不做任何上幣保證:8月10日消息,幣安發布《關于支持以太坊合并計劃的公告》,據公告內容顯示.
1900/1/1 0:00:00


