






 BTC/HKD+0.1%
BTC/HKD+0.1% ETH/HKD+0.29%
ETH/HKD+0.29% LTC/HKD+0.19%
LTC/HKD+0.19% DOT/HKD-0.13%
DOT/HKD-0.13% ADA/HKD+0.49%
ADA/HKD+0.49% SOL/HKD+0.47%
SOL/HKD+0.47% XRP/HKD+0.41%
XRP/HKD+0.41% DOGE/US+0.37%
DOGE/US+0.37%ChatGPT引爆的AI熱潮也“燒到了”金融圈,彭博社重磅發布為金融界打造的大型語言模型——BloombergGPT。
3月30日,根據彭博社最新發布的報告顯示,其構建迄今為止最大的特定領域數據集,并訓練了專門用于金融領域的LLM,開發了擁有500億參數的語言模型——BloombergGPT。
報告顯示,該模型依托彭博社的大量金融數據源,構建了一個3630億個標簽的數據集,支持金融行業內的各類任務。該模型在金融任務上的表現遠超過現有模型,且在通用場景上的表現與現有模型也能一較高下。
一般來說,在NLP領域,參數數量和復雜程度之間具有正相關性,GPT-3.5模型的參數量為2000億,GPT-3的參數量為1750億。

Filecoin去中心化金融服務平臺DeFIL正式上線幣安智能鏈BSC:據最新消息,Filecoin去中心化金融服務平臺DeFIL 2.0 于區塊高度10525502正式上線幣安智能鏈BSC,并同步開啟所有功能,包括算力NFT和FILST鑄造、eFIL跨鏈、流動性挖礦、質押借貸等。同時,defil于9月1日11:00 (UTC+8) ~9月6日 11:00 (UTC+8)期間推出《DeFIL 2.0正式上線BSC!10,000 DFL等你來贏!》活動。活動期間,在PancakeSwap上FILST凈買入量(買入-賣出)>0 FILST的用戶即可按比例參與瓜分10,000 DFL獎勵。
注:DeFIL 2.0在BSC上的交互需要用戶在支持BSC的錢包應用中從以太坊切換為BSC網絡,并且在交易所購買少量BNB轉入錢包用作智能合約交互所需的Gas費用。[2021/9/1 22:51:51]
關于BloombergGPT
北京市政府副秘書長:北京將持續推進建設法定數字貨幣試驗區和數字金融體系:北京市政府副秘書長張勁松:北京將持續推進建設法定數字貨幣試驗區和數字金融體系,將探索制定跨境數據流動和交易規則,支持金融機構和大型科技企業設立金融科技公司,設立國家金融科技風險監控中心等。(新華財經)[2020/11/27 22:18:28]
報告指出,研究人員利用彭博社現有的數據,對資源進行創建、收集和整理,通過構建迄今為止最大的特定領域數據集來完成BloomberGPT,并基于通用和金融業務的場景進行混合模型訓練:
彭博社主要是一家金融數據公司,數據分析師在公司成立的四十年的時間里收集了大量的金融文件,擁有廣泛的金融數據檔案,涵蓋了一系列的主題。
我們將這些數據添加到公共數據集中,以創建一個擁有超過7000億個標簽的大型訓練語料庫。
動態 | 元界DNA聯合創始人黃連金出席第十六屆中國國際金融論壇:2019年12月19日,第十六屆中國國際金融論壇在上海舉行,中國電子學會區塊鏈分會專家委員、元界DNA聯合創始人黃連金受邀參會。當天下午,黃連金出席以“區塊鏈與金融安全新技術應用”為主題的圓桌論壇,并表示金融安全涉及多方面,在跟區塊鏈融合過程中交易速度和數據安全問題都亟需解決,像元界DNA的雙鏈網絡架構和閃電網絡技術即為了提升交易速度。另外中心化數字身份是數據安全問題的主要原因,而元界DNA要做的就是保證數據的私有化安全和去中心化數字身份。
據悉,中國國際金融論壇創辦于2004年,每年一屆,第十六屆中國國際金融論壇由國際銀行業聯合會、國際資本市場協會、金融時報社、中國銀行業協會共同主辦。本屆論壇邀請了中外金融監管機構領導、中外資銀行、國內外私募股權基金、金融中介服務機構、投行、證券公司及高成長性企業負責人、專家學者等嘉賓出席。論壇旨在通過高層次的對話、交流,對中國金融業發展的前沿問題進行深入探討。[2019/12/19]
使用這個訓練語料庫的一部分,我們訓練了一個具有彭博風格的,達500億參數的模型,該模型是根據Hoffmann和LeScao等人的指導方針設計,基于通用和金融業務的場景進行混合模型訓練。
聲音 | 金融壹賬通王夢寒:行業發展需要更多的企業一起共建弱中心化的網絡生態:據人民網消息,金融壹賬通高級產品總監王夢寒表示,小范圍試點項目的落地雖具有探索意義,但無法充分發揮區塊鏈技術的價值。行業的進一步發展,需要更多的企業一起參與進來,共建弱中心化的網絡生態,以實現更充分的數據共享和效率提升。如何說服傳統金融行業用戶接受弱中心化理念,建立規模化的網絡生態,形成全新的合作模式共謀發展,是區塊鏈發展面臨的另一挑戰。[2019/6/2]
結果表明,我們的混合訓練方法使我們的模型在金融任務上的表現大大超過了現有的模型,而在通用場景上的表現則與之相當甚至優于現有模型。

動態 | 臺灣高雄市“政府經濟發展局”設立科技創新園區 助力區塊鏈等金融科技創業:據聯合新聞網消息,臺灣高雄市“政府經濟發展局”在財稅大樓設了“高雄智慧科技創新園區(KO-IN智高點)”,助力人工智慧、物聯網、區塊鏈以及金融科技等科技產業創業的青年筑夢,預計6月正式營運。[2019/4/11]
1.BloombergGPT優勢:特定領域模型仍有其不可替代性且彭博數據來源可靠
在論文中,彭博社指出,現階段,通用的自然語言處理模型可以涵蓋許多領域,但針對特定領域模型仍有其不可替代性,因彭博社的大多數應用均為金融領域,著手構建了一個針對金融領域的模型尤其優勢,同時可以在通用LLM基準測試上保持競爭力:
除了構建金融領域的LLM外,本文的經驗也為其他研究領域的專用模型提供了參考。我們的方法是在特定領域和一般數據源上訓練LLM,以開發在特定領域和通用基準上表現優異的模型。
此外,我們的訓練數據不同于傳統的網絡爬取數據,網絡上的數據總有重復和錯誤,但我們的數據來源可靠。

2.BloombergGPT的訓練數據集:
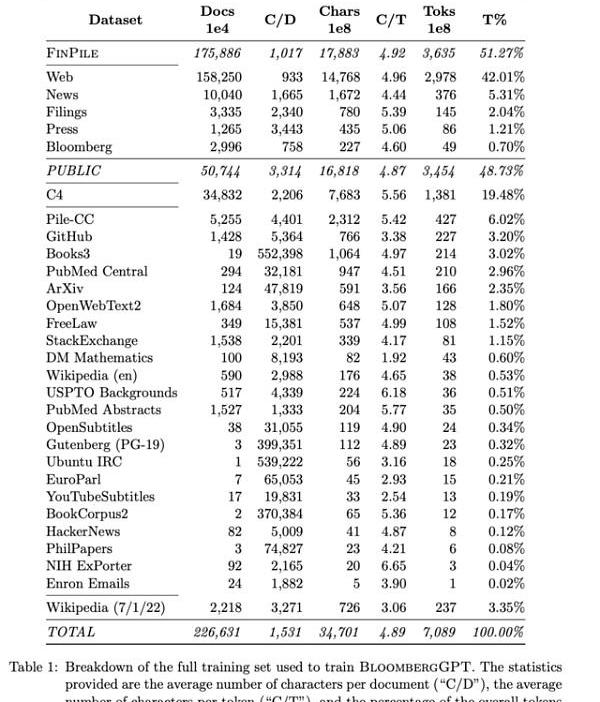
BloombergGPT的訓練數據庫名為FINPILE,由一系列英文金融信息組成,包括新聞、文件、新聞稿、網絡爬取的金融文件以及提取到的社交媒體消息。
為了提高數據質量,FINPILE數據集也使用了公共數據集,例如ThePile、C4和Wikipedia。FINPILE的訓練數據集中大約一半是特定領域的文本,一半是通用文本。為了提高數據質量,每個數據集都進行了去重處理。
對金融領域的理解更準
報告指出,在金融領域中的自然語言處理在通用模型中也很常見,但是,針對金融領域,這些任務執行時將面臨挑戰:
以情感分析為例,一個題為“某公司將裁員1萬人”,在一般意義上表達了負面情感,但在金融情感方面,它有時可能被認為是積極的,因為它可能導致公司的股價或投資者信心增加。
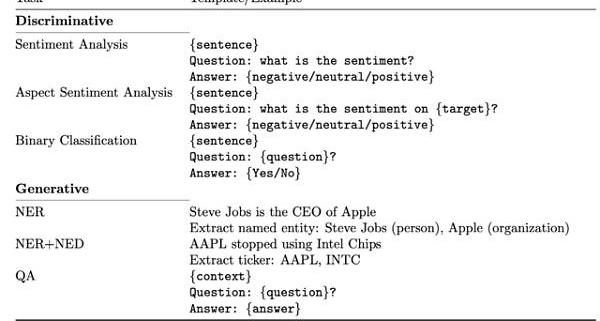
報告指出,從測試來看,BloombergGPT在五項任務中的四項表現最佳,在NER中排名第二。因此,BloombergGPT有其優勢性。
測試一:ConvFinQA數據集是一個針對金融領域的問答數據集,包括從新聞文章中提取出的問題和答案,旨在測試模型對金融領域相關問題的理解和推理能力。
測試二:FiQASA,第二個情感分析任務,測試英語金融新聞和社交媒體標題中的情感走向。
測試三:標題,數據集包括關于黃金商品領域的英文新聞標題,標注了不同的子集。任務是判斷新聞標題是否包含特定信息,例如價格上漲或價格下跌等。
測試四:FPB,金融短語庫數據集包括來自金融新聞的句子情緒分類任務。
測試五:NER,命名實體識別任務,針對從提交給SEC的金融協議中收集金融數據,進行信用風險評估。
對于ConvFinQA來說,這個差距尤為顯著,因為它需要使用對話式輸入來對表格進行推理并生成答案,具有一定挑戰性。
ChatGPT為彭博點贊
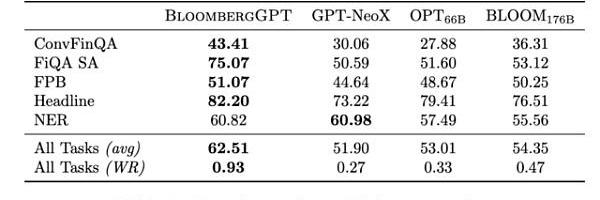
華爾街見聞就這個問題專門詢問了ChatGPT,ChatGPT認為BloombergGPT是一項很有意義的技術進步:
它是專門為金融領域開發的一種語言模型,可以更好地處理金融領域的數據和任務,并且在金融領域的基準測試中表現出色。
這將有助于金融從業者更好地理解和應用自然語言處理技術,促進金融科技的發展。同時,BloombergGPT還可以為其他領域的語言模型的發展提供參考和借鑒。總的來說,BloombergGPT是一個有益的技術創新。
4月9日消息,MetaSleuth發推稱,SushiSwapRouteProcessor2合約攻擊事件導致0xsifu損失1800枚ETH。第一個攻擊者已歸還90枚ETH.
1900/1/1 0:00:00TMT行業的高管看到了“元宇宙”在提高利潤和降低運營費用方面給企業帶來的潛力。但也有類似比例的人承認,盡管元宇宙有豐富的潛力,但它仍需要進一步的完善和發展.
1900/1/1 0:00:00DeFi數據 1、DeFi代幣總市值:480.28億美元 DeFi總市值及前十代幣數據來源:coingecko2、過去24小時去中心化交易所的交易量24.
1900/1/1 0:00:00這兩天,一篇關于“GPT-4救了我狗的命”的帖子屬實有點火:短短一兩天就有數千人轉發,上萬人點贊,網友在評論區討論得熱火朝天.
1900/1/1 0:00:00這篇文章將展示基于2-of-2MPC技術的MACI匿名化方案的具體實現。本文核心內容主要分為三個部分:從任意算法到邏輯電路的實現;從邏輯電路到混淆電路的實現;利用不經意傳輸實現多方安全計算.
1900/1/1 0:00:00原文:《將零知識證明引入比特幣,ZeroSync要做什么?》作者:Karen,ForesightNews如果在比特幣上引入零知識證明.
1900/1/1 0:00:00


