






 BTC/HKD-0.14%
BTC/HKD-0.14% ETH/HKD-0.47%
ETH/HKD-0.47% LTC/HKD-2.6%
LTC/HKD-2.6% DOT/HKD-3.31%
DOT/HKD-3.31% ADA/HKD-1.32%
ADA/HKD-1.32% SOL/HKD-0.69%
SOL/HKD-0.69% XRP/HKD+0.48%
XRP/HKD+0.48% DOGE/US-0.45%
DOGE/US-0.45%本文來源:未央網,作者:黃銳
引言
這幾年,學術和產業界對區塊鏈的理解和應用產生了大量誤區,本人也在過去的文章中逐步澄清和重新定義。不過,總覺得意猶未盡,沒有專門立題成章。最近由于正在設計分布式產業協作模型,每到區塊鏈技術運用精妙之處,覺得需要有系列文章來逐一解釋這些誤解。希望通過本人的反復倡導,可以為區塊鏈產業運用提供更多的方案和定義。
這次我們首先討論“區塊鏈是共享數據庫”這個說法到底有沒有問題。在百度百科這樣描述區塊鏈:“區塊鏈是一個信息技術領域的術語。從本質上講,它是一個共享數據庫,存儲于其中的數據或信息,具有“不可偽造”“全程留痕”“可以追溯”“公開透明”“集體維護”等特征。”可以說大部分認為區塊鏈是一種共享數據庫的說法,受百度百科影響比較大。
接下來,我們就分析一下什么是共享數據庫?
一、什么是共享數據庫?
本人通過“知網”搜索“共享數據庫”關鍵字,并未發現直接匹配的論文,更多是關于數據共享模式的相關論文;通過百度百科詞條搜索也沒有發現“共享數據庫”的概念描述,倒是有“共享存儲”。可以說,一直以來“共享數據庫”就不是學術和系統軟件實踐的概念,“共享數據庫”更多的是互聯網造詞的畸形產物之一。
WarnerMedia子公司Turner Sports推出區塊鏈游戲平臺:金色財經報道,跨國媒體和娛樂集團WarnerMedia通過其子公司Turner Sports加入了區塊鏈游戲生態系統。該公司最近宣布推出Blocklete Games平臺,玩家可以通過NFT來收集、訓練、交易并與數字運動員比賽,同時獲得現金獎勵。此外該公司與BitPay合作,使用戶能夠使用BTC、BCH、XRP、ETH和其他四個與美元掛鉤的穩定幣購買Blockletes和Blocklete收藏品。[2020/9/17]
這是因為,無論從數據集成和共享模式分析,還是從數據庫分類分析看,“共享數據庫”都是一種偽命題。
首先,從數據庫的定義上看:“數據庫是按照數據結構來組織、存儲和管理數據的倉庫,是一個長期存儲在計算機內的、有組織的、可共享的、統一管理的大量數據的集合”,也就是說數據可共享本身就是數據庫的基礎功能之一,不需要額外使用區塊鏈技術來建立數據庫的數據共享能力。
其次,從數據庫分類看,目前常見分類按照數據結構的組織不同,可分為:“關系型數據庫”和“NoSQL數據庫”;按照部署模式不同,可分為:“單機數據庫”和“分布式數據庫”等,也從未出現過按照數據共享程度分類的數據庫。
北京市海淀區政協開展“區塊鏈”等重點提案落實情況的視察和協商活動:據海淀區政協消息,7月16日上午,區政協副主席丁志明帶領有關“區塊鏈”方面的提案人和部分政協委員來到互聯網金融中心,參觀北京微芯邊緣計算研究院,并召開座談會,了解中關村科學城管委會、區政務服務管理局等單位對區政協區塊鏈技術相關提案的辦理情況,提案委主任劉彥主持會議。丁志明強調,要認真謀劃推動區塊鏈技術應用和產業落地,努力打造海淀區成為北京市最具影響力的區塊鏈科技創新高地、應用示范高地。相關單位要加強統籌,增強工作合力,完善體制機制,落實相關支持政策,為推動區塊鏈產業創新發展營造良好環境。[2020/7/20]
再者,從數據共享方式上看,業界常采用數據集成,實現把不同來源、格式、特點性質的數據在邏輯上或物理上有機地集中,從而為企業提供全面的數據共享。通常采用聯邦式、基于中間件模型和數據倉庫等方法來構造數據集成的系統,并且已有很多成熟的框架可以利用。
所以,無論是數據庫技術,還是企業數據共享模式的發展都從未出現過“共享數據庫”這個概念,因為開發數據庫軟件的初衷本質上就是解決數據的組織、存儲、管理和共享的。
二、為什么會認為區塊鏈是共享數據庫
上面講到“區塊鏈是一種共享數據庫嗎?”是一種偽命題,因為數據庫的使命之一就是提升數據的訪問和共享便捷性。那我們為什么有這樣的定義呢?我猜測,“區塊鏈是一種共享數據庫”主要還是受一些通用底層區塊鏈平臺或產品的影響。
動態 | 區塊鏈可能在5年為印度創造50億美元的經濟價值:據Economictimes消息,近日,印度軟件和服務業企業行業協會(Nasscom)的一位高級官員在一次訪談中表示,通過提高生產率和降低成本,區塊鏈技術有望在未來五年內,為印度創造50億美元的經濟價值。[2018/7/27]
首先,大部分的公鏈平臺,例如:Bitccoin、Ethereum、EOS等,本身并不是一個通用底層區塊鏈平臺,他們都是以點對點資產交易為核心構建區塊鏈相關技術的組合應用,包括:加密技術、分布式技術、P2P數據傳輸、共識算法、鏈式數據結構、博弈論等。技術的運用是為點對點、安全、高效的資產交易達成服務的。所以在非資產處理的行業領域,例如:政務、工業、供應鏈等,直接使用基于公鏈的區塊鏈技術往往會格格不入。由于公鏈平臺業務目的是明確的,所以大家不會去討論BitCoin是否是一個共享數據庫的問題。
其次,在大部分已開展聯盟鏈應用的行業中,底層大量采用ApacheHyperledger系列平臺,受Hyperledger的影響頗深。以Hyperledger核心的Fabric為例,Fabric是一個業務目的不明確的通用區塊鏈平臺。從下圖可以看到Fabric的節點主要由智能合約和分布式賬本構成。而節點中的數據主要由分布式賬本Ledger存儲。
行情 | A股開盤:區塊鏈板塊整體下跌0.16%:A股開盤,區塊鏈板塊整體下跌0.16%,84只概念股中,31只上漲,40只下跌,9只平盤,5只停牌。漲幅前三為:潤和軟件(+3.43%),金證股份(+2.82%),華軟科技(+2.77%)。跌幅前三為:歐浦智網(-9.95%),科藍軟件(-8.37%),易見股份(-1.27%)。[2018/7/3]
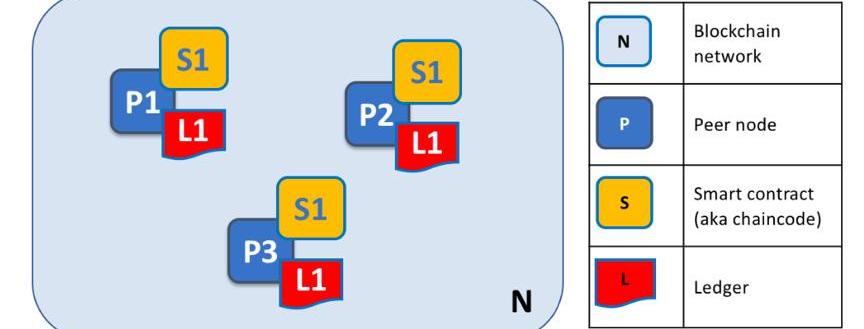
Fabric節點構成
來源:HyperledgerFabric技術白皮書
而分布式賬本Ledger又主要由Blockchain和全局狀態構成,全局狀態的更新被區塊中的交易Transactions觸發和決定。見下圖:
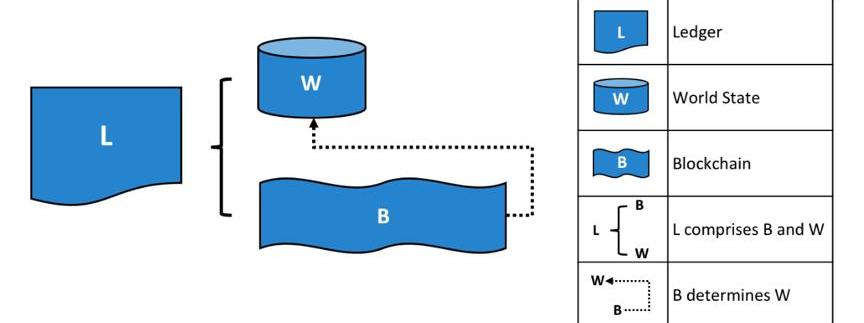
Fabric賬本構成
來源:HyperledgerFabric技術白皮書
由下圖可見,分布式賬本Ledger中的全局狀態WorldState本質確實是一種分布式的KV存儲模型,再配合分布式節點網絡,就不難解釋為什么會認為區塊鏈是一種共享數據庫了。
新加坡科學院院士黃銘鈞:用區塊鏈技術構建以患者為中心的醫療服務新模式:新加坡科學院院士、新加坡國立大學杰出教授浙江省人工智能發展委員會委員黃銘鈞在“大數據、人工智能、區塊鏈在醫療健康領域的應用和進展”高端研討會上發表主題報告時說,目前的醫療信息化建設仍然以業務為核心,以患者和醫囑為核心的服務模式仍然面臨數據可及性和數據可用性的挑戰。理想的醫療數據共享體系應以患者為中心,患者擁有最高權限管理自己的病史記錄,并且有權為不同的醫療服務提供方(包括醫院)設定不同的訪問權限。區塊鏈為構建以患者為中心的醫療服務新模式提供了基礎。[2018/3/28]
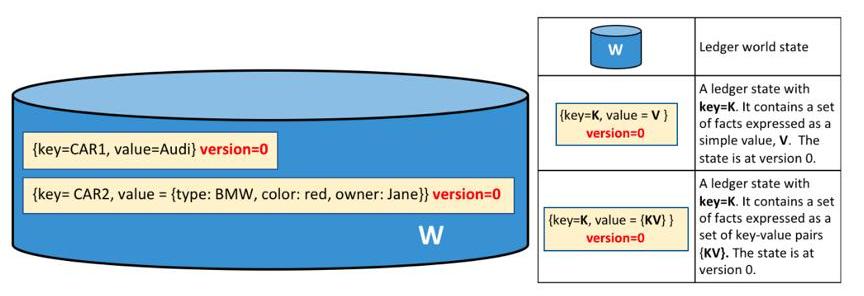
Fabric狀態模型
來源:HyperledgerFabric技術白皮書
上面已經提到,Fabric是一種業務目的不明確的通用區塊鏈平臺,在Fabric的賬本模型Ledger中,其實和我們日常理解的金融賬本并沒有直接關系,Ledger只是一種通用KV存儲模型,你可以存儲任意數據。在Fabric實際使用過程中,如果沒有領域模型驅動,Fabric就真是一個分布式數據存儲架構。
受這個因素影響,實際上我們在區塊鏈行業應用中,大量采用Fabric的全局狀態存儲WorldState,實現分布式存儲鏈。我在其他文章已經反復強調了,如果把區塊鏈定位為分布式的數據存儲機制,那和目前常用的分布式數據庫相比沒有任何技術優勢,只是實現更復雜,效率更低而已。
三、數據的共享與數據存儲結構無關
通過上面的分析,也確實可以把以Fabric為代表的區塊鏈通用平臺,定義為分布式數據存儲模型,但這種分布式存儲機制可以帶來數據共享和開放嗎?這里有個誤區,是我們片面的理解為,數據分布式可帶來數據的共享,但本文想強調,數據是否共享與存儲結構和部署模式無關。
數據的存儲結構和部署模式是物理模型,而數據的共享是業務模型。在當下“數據即資產”以及個人隱私保護和商業數據安全得到民眾和輿論強化理解的當下,決定數據是否共享的關鍵,不是數據如何存儲和部署,而是數據共享的業務必要性和多方參與者的利益是否得到平衡和保障。簡單利用分布式存儲機制解決“信息孤島”問題,顯然是異想天開了。
而且,大部分“信息孤島”的問題,恰恰是數據分散存儲和管理造成的,可以說數據的分布式是現狀,而不是前景。解決數據分散造成的“信息孤島”問題,首先要區分數據主權關系。在單一數據主權下最高效的方法是數據集成,通過數據聯邦、數據中間件和數據倉庫等方式實現數據的匯聚;在多方數據主權關系下,則是通過法律強制或商業模式驅動,在合法合規的前提下讓數據在數據應用相關方之間安全流動。
在無法建立數據集成的環境下,例如:多方數據主權、集成成本和法律限制條件,確實可以采用區塊鏈技術建立數據可交易、可流動、可監管的可信數據共享網絡。但這時區塊鏈技術應用重點恰恰不是分布式的數據存儲,而是數據資產的交易。如果沒有建立數據資產交易模型,簡單利用Fabric的全局狀態,是無法實現數據共享的。
其實,以Bitcoin為代表的經典區塊鏈技術,已經證明了區塊鏈分布式節點中的數據存儲只是為了保障各節點,可以本地化、高效的驗證交易數據的真偽,而不是為數據共享為最終目的。
四、新技術驅動總是先帶來啞鈴效應
進入互聯網Web2.0時代以來,大量新技術,新名詞涌入產業界,從大數據、AI、5G、區塊鏈再到今年的量子計算,每一次的新技術和產業結合都避免不了在國內產業圈出現技術認知的“啞鈴效應”,即:啞鈴的一頭是高度概念化、抽象化,而另一頭是高度的實例化和工具化。
區塊鏈技術的興起也是如此,一邊是從概念化和抽象化上刻畫區塊鏈是一種去中心化,用網絡自治代替中心化系統的價值互聯網;而另一邊則是將區塊鏈描述為共享數據庫,一種分布式存儲工具。為什么會產生這樣的認知呢?我想很大原因是,一種新技術的突然興起,往往只是被幾篇論文、幾個應用場景點燃,但在廣泛領域的應用型配套研究還未完全跟上,采用高度概念化、抽象化或實例化、工具化的定義,總能在現實世界找到映射關系,這是一種低成本的解釋路徑。
可以說,新技術發展的啞鈴效應是一個必然過程,但隨著新技術在領域實踐中的知識積累和模型沉淀,將會不斷修正啞鈴的兩端,讓價值認知更為平滑、實用。愛因斯坦說過:“你無法在制造問題的同一思維層次上解決這個問題”,看待新技術往往不能直接從現實事物中直接匹配和映射,而是需要以創新思維在應用領域發展和完善新技術的定義和價值。
總結
區塊鏈技術在某種程度上確實可以充當分布式數據庫或數據共享機制使用,但在實際應用中與傳統數據集成框架相比,并無優勢。同時由于采用分布式共識算法、P2P網絡傳輸和區塊數據結構等技術,系統復雜度更高、性能和可維護性更差。這么大的代價只是為了建立分布式一致性的存儲機制顯然是得不償失的,也沒有實際商業前途。利用區塊鏈技術需要關注分布式的對等、安全、公平的交易環境的搭建上,以優化數據交易環境為前提,間接實現數據充分共享和利用。可以說在數據共享領域,區塊鏈技術只是基礎條件之一,而不是絕對因素。在數據所有權分散的環境下,決定數據是否可以共享,最重要的是業務和商業模型的確立。
參考文獻:
百度百科https://baike.baidu.com/item/數據庫/103728
Apachehyperledger-fabric-readthedocs-io-en-release-2.0.pdf
相關文章:
《我們真的了解區塊鏈嗎?重新理解區塊鏈商業價值》
11月23日,浙江省經濟和信息化廳發布關于向社會公開征求《浙江省區塊鏈技術和產業發展規劃》意見建議的公告.
1900/1/1 0:00:00背景 過去幾周來,uLABS從社區成員那里獲得了靈感,并在幾乎沒有UMA開發團隊的幫助下在主網上部署了UMA合約.
1900/1/1 0:00:00一件接著一件,Compound動輒千萬美金資產清算事件的爆出,讓從前備受推崇的預言機成為眾矢之的.
1900/1/1 0:00:00原標題:《瘋狂合作背后:YFI創始人的DeFi小宇宙》自從宣布即將推出YearnVaultsv2以來.
1900/1/1 0:00:00|合規聯盟原創出品| 近來幣圈一直不太平,國內外各種大小事件持續發酵,前有OK創始人徐明星被抓導致平臺無法提幣,后有福布斯揭露幣安躲避美國監管,接著又傳出火幣COO被調查.
1900/1/1 0:00:00加密貨幣整個資產類別都是捆綁在一起,每當比特幣上漲時,其他加密貨幣必然會隨之上漲,它發生在2017年,現在發生在2020年.
1900/1/1 0:00:00


